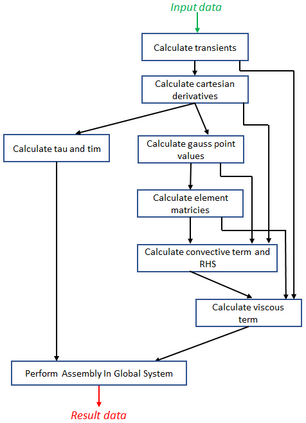
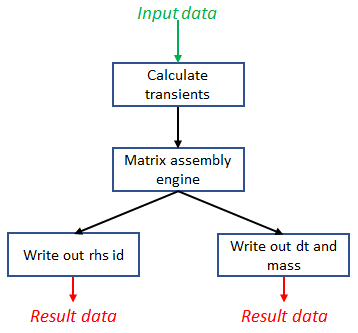
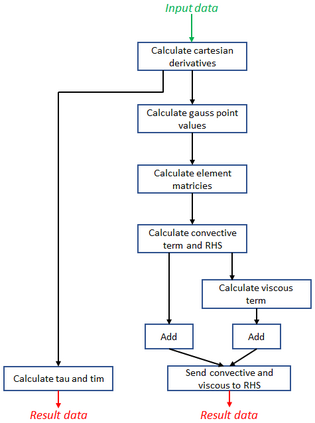
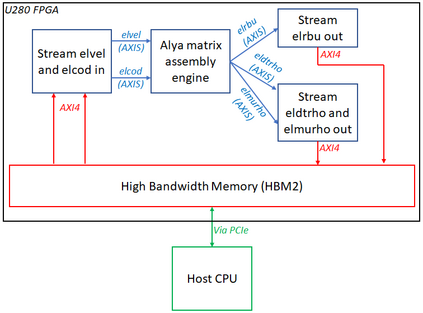
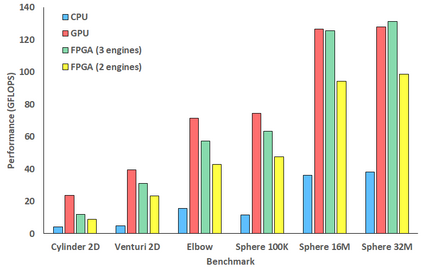
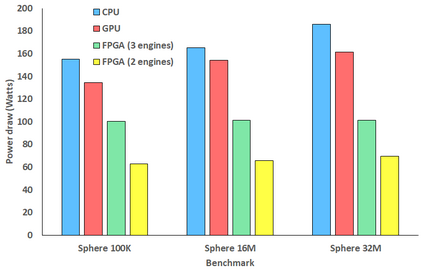
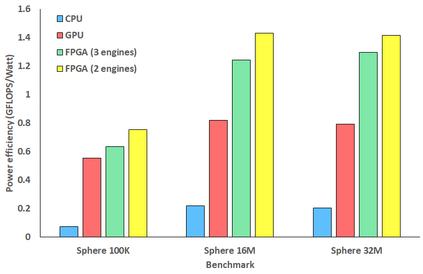
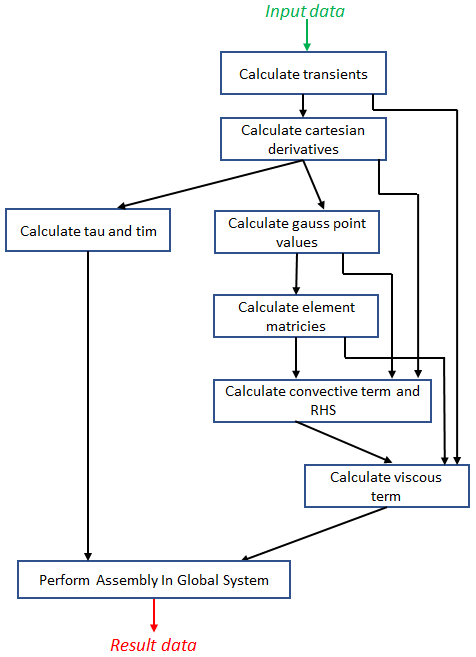
Engineering is an important domain for supercomputing, with the Alya model being a popular code for undertaking such simulations. With ever increasing demand from users to model larger, more complex systems at reduced time to solution it is important to explore the role that novel hardware technologies, such as FPGAs, can play in accelerating these workloads on future exascale systems. In this paper we explore the porting of Alya's incompressible flow matrix assembly kernel, which accounts for a large proportion of the model runtime, onto FPGAs. After describing in detail successful strategies for optimisation at the kernel level, we then explore sharing the workload between the FPGA and host CPU, mapping most appropriate parts of the kernel between these technologies, enabling us to more effectively exploit the FPGA. We then compare the performance of our approach on a Xilinx Alveo U280 against a 24-core Xeon Platinum CPU and Nvidia V100 GPU, with the FPGA significantly out-performing the CPU and performing comparably against the GPU, whilst drawing substantially less power. The result of this work is both an experience report describing appropriate dataflow optimisations which we believe can be applied more widely as a case-study across HPC codes, and a performance comparison for this specific workload that demonstrates the potential for FPGAs in accelerating HPC engineering simulations.
翻译:工程是超comput 的一个重要领域, Alya 模型是进行此类模拟的流行代码。 随着用户对更大规模、更复杂的系统模型的需求日益增长,在更短的时间内,在更短的时间内,我们应探索新硬件技术(如FPGAs)在加快未来缩略图系统工作量方面可以发挥的作用。在本文中,我们探讨将Alya的压抑性流质矩阵组件内核部分的运行速度占模型运行时间很大比例的24-CELinx Alveo U280与24-Center Xeon Platinum CPU和Nvidia V100 GPU的运行速度。在详细描述核心一级优化的成功战略之后,我们然后探索在FPGA和主办CPU之间分担工作量,绘制这些技术之间最合适的内核部分,使我们能够更有效地利用FPGGAGA。 然后,我们将我们在Xlinx Alveo U280上的方法与24- Xeon Platinum PC CPU和Nvidia V100 GPU GBU的运行过程的运行情况进行比较,我们可以对这个具体的工作进行更深入的进度进行比较。