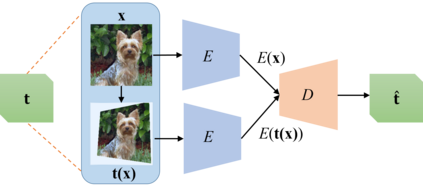
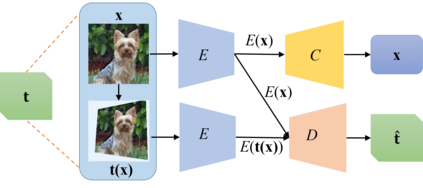
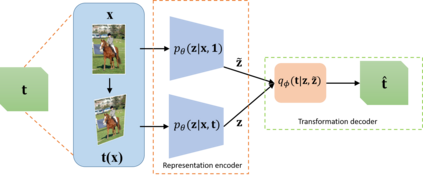
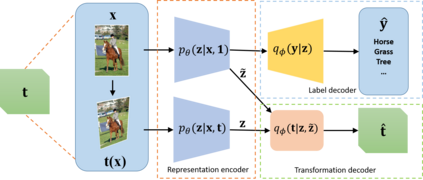
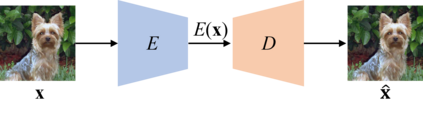Transformation Equivariant Representations (TERs) aim to capture the intrinsic visual structures that equivary to various transformations by expanding the notion of {\em translation} equivariance underlying the success of Convolutional Neural Networks (CNNs). For this purpose, we present both deterministic AutoEncoding Transformations (AET) and probabilistic AutoEncoding Variational Transformations (AVT) models to learn visual representations from generic groups of transformations. While the AET is trained by directly decoding the transformations from the learned representations, the AVT is trained by maximizing the joint mutual information between the learned representation and transformations. This results in Generalized TERs (GTERs) equivariant against transformations in a more general fashion by capturing complex patterns of visual structures beyond the conventional linear equivariance under a transformation group. The presented approach can be extended to (semi-)supervised models by jointly maximizing the mutual information of the learned representation with both labels and transformations. Experiments demonstrate the proposed models outperform the state-of-the-art models in both unsupervised and (semi-)supervised tasks.
翻译:变异变异表(变异变异图示)旨在捕捉与各种变异相对均匀的内在视觉结构,通过扩大演进神经网络成功背后的 ~ em 翻译 + + + Q + 概念,使演进神经网络( CNNs ) 的概念得以扩大,从而获取与各种变异相对等化的内在视觉结构。为此,我们提出了确定性自动编码变异模型( AET) 和 概率自动编码变异变异模型( AVT), 以学习通用变异图示, 学习通用变异图示直接解码, 培训AVT, 最大限度地利用学习性表示和变异之间的联合信息, 培训AVT 。 结果是, 通过在变异组中捕捉超出常规线性变异性的视觉结构复杂模式( AVTERs) 和变异变组模式( ), 其提出的方法可以推广到( 缩式), 与标签和变组和变组共同尽量扩大所学化的相互信息。