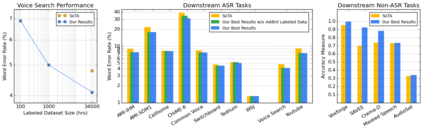
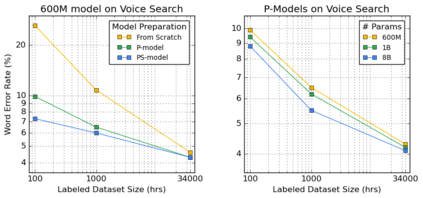
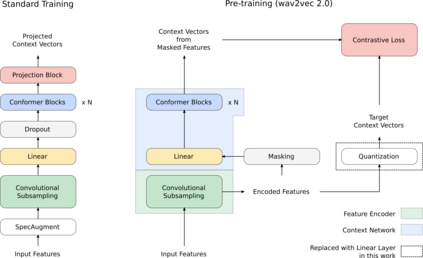
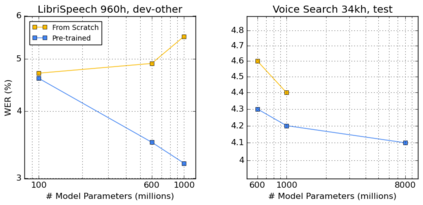
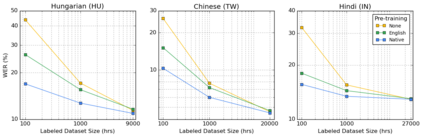
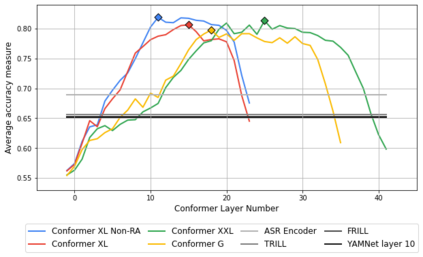
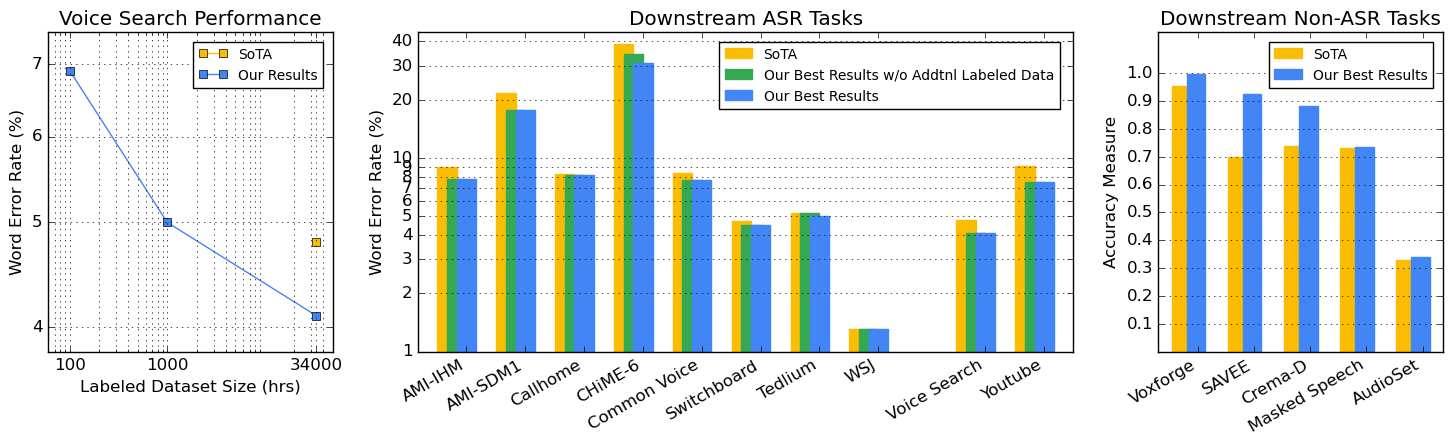
We summarize the results of a host of efforts using giant automatic speech recognition (ASR) models pre-trained using large, diverse unlabeled datasets containing approximately a million hours of audio. We find that the combination of pre-training, self-training and scaling up model size greatly increases data efficiency, even for extremely large tasks with tens of thousands of hours of labeled data. In particular, on an ASR task with 34k hours of labeled data, by fine-tuning an 8 billion parameter pre-trained Conformer model we can match state-of-the-art (SoTA) performance with only 3% of the training data and significantly improve SoTA with the full training set. We also report on the universal benefits gained from using big pre-trained and self-trained models for a large set of downstream tasks that cover a wide range of speech domains and span multiple orders of magnitudes of dataset sizes, including obtaining SoTA performance on many public benchmarks. In addition, we utilize the learned representation of pre-trained networks to achieve SoTA results on non-ASR tasks.
翻译:我们总结了使用大型自动语音识别(ASR)模型所做的大量努力的结果,这些模型是使用含有大约100万小时音频的大型、多种无标签数据集进行预先培训的。我们发现,将培训前、自我培训和扩大模型规模结合起来,大大提高了数据效率,即使对于涉及数万小时标签数据的巨大任务也是如此。特别是,在具有34千小时标签数据的ASR任务方面,我们通过微调一个80亿参数的预培训后模型,我们可以将培训前最先进的功能与仅3%的培训数据匹配起来,并大大改进SoTA全套培训。我们还报告了使用大型培训前和自我培训模式,用于涵盖广泛的语音领域并跨越多层次数据集大小的大型下游任务,包括在许多公共基准上获得SoTA的绩效,从而获得普遍效益。此外,我们利用培训前网络的经验,在非ASA任务上取得结果。