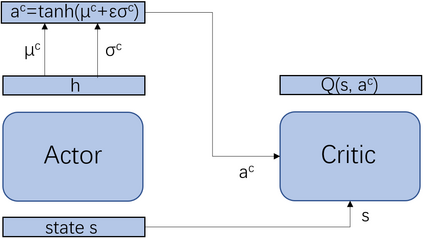
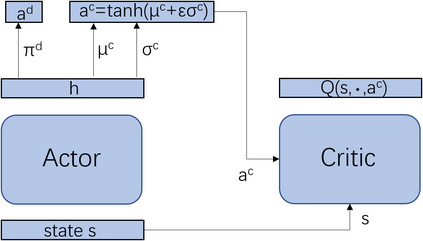
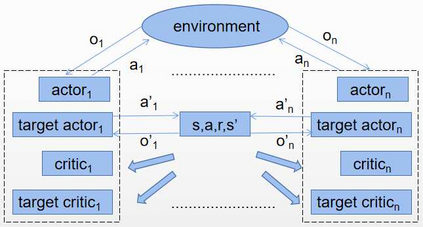
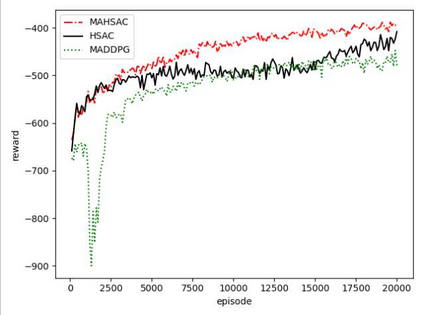
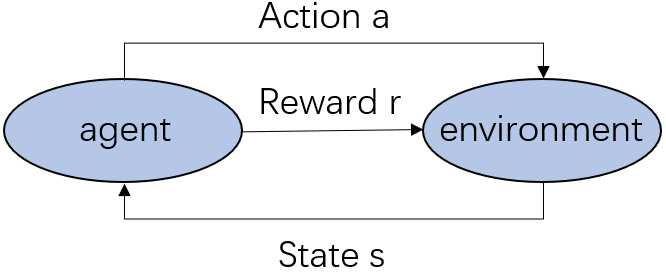
Multi-agent deep reinforcement learning has been applied to address a variety of complex problems with either discrete or continuous action spaces and achieved great success. However, most real-world environments cannot be described by only discrete action spaces or only continuous action spaces. And there are few works having ever utilized deep reinforcement learning (drl) to multi-agent problems with hybrid action spaces. Therefore, we propose a novel algorithm: Deep Multi-Agent Hybrid Soft Actor-Critic (MAHSAC) to fill this gap. This algorithm follows the centralized training but decentralized execution (CTDE) paradigm, and extend the Soft Actor-Critic algorithm (SAC) to handle hybrid action space problems in Multi-Agent environments based on maximum entropy. Our experiences are running on an easy multi-agent particle world with a continuous observation and discrete action space, along with some basic simulated physics. The experimental results show that MAHSAC has good performance in training speed, stability, and anti-interference ability. At the same time, it outperforms existing independent deep hybrid learning method in cooperative scenarios and competitive scenarios.
翻译:多试剂深度强化学习已被应用于解决不同或连续行动空间的各种复杂问题,并取得了巨大成功。然而,大多数现实世界环境无法仅以离散行动空间或仅以连续行动空间来描述。对于混合行动空间的多试剂问题,很少有工作曾利用过深度强化学习(drl)解决过多试剂问题。因此,我们提议了一个新的算法:深多剂混合软体行为者-Critic(MAHSAC)来填补这一空白。这一算法遵循了集中培训但分散执行的模式(CTDE),并扩展了Soft Actor-Critic 算法(SAC ), 以处理基于最大变速率的多剂环境中的混合行动空间问题。我们的经验是在一个容易的多剂粒子世界中运行的,这个世界有连续的观察和离散行动空间,以及一些基本的模拟物理学。实验结果表明,MAHAC在培训速度、稳定性和反干扰能力方面表现良好。与此同时,它超越了合作情景和竞争性情景中现有的独立深层混合学习方法。