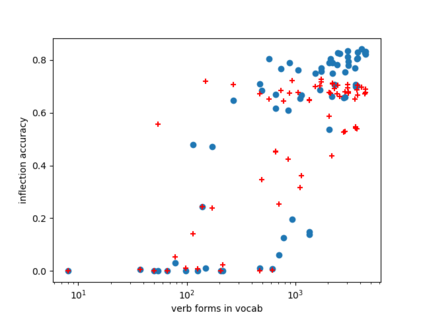
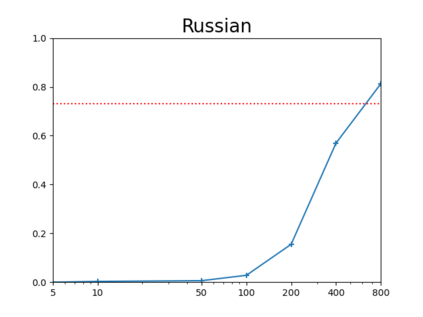
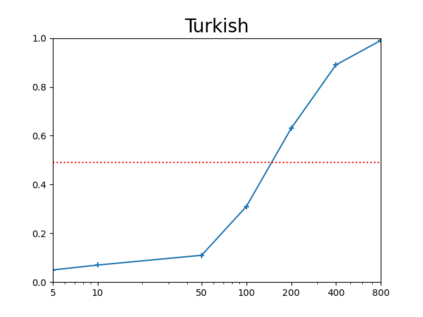
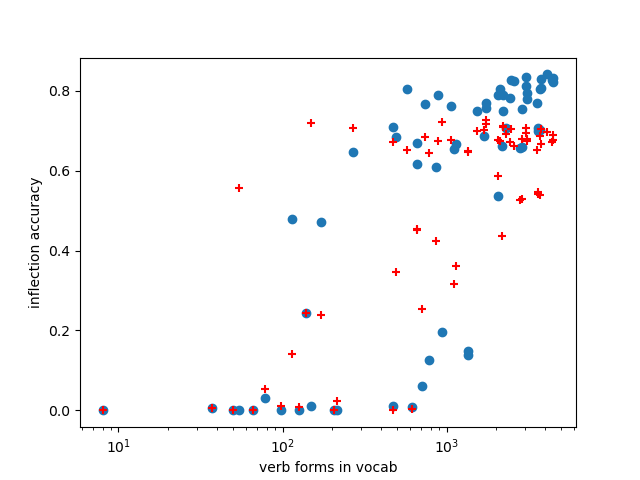
Neural models for the various flavours of morphological inflection tasks have proven to be extremely accurate given ample labeled data -- data that may be slow and costly to obtain. In this work we aim to overcome this annotation bottleneck by bootstrapping labeled data from a seed as little as {\em five} labeled paradigms, accompanied by a large bulk of unlabeled text. Our approach exploits different kinds of regularities in morphological systems in a two-phased setup, where word tagging based on {\em analogies} is followed by word pairing based on {\em distances}. We experiment with the Paradigm Cell Filling Problem over eight typologically different languages, and find that, in languages with relatively simple morphology, orthographic regularities on their own allow inflection models to achieve respectable accuracy. Combined orthographic and semantic regularities alleviate difficulties with particularly complex morpho-phonological systems. Our results suggest that hand-crafting many tagged examples might be an unnecessary effort. However, more work is needed in order to address rarely used forms.
翻译:各种形态变异任务神经模型非常精确, 并附有大量标签数据 -- -- 这些数据可能缓慢, 且成本高昂。 在这项工作中, 我们的目标是通过从一个几乎只有 ~ 5 标记的种子中提取标签数据来克服这个注解瓶颈, 并伴之以大量未贴标签的文字。 我们的方法在分两阶段设置的形态系统中利用了不同种类的规律。 在这种结构中, 以 ~ em 类比 } 为基础的单词标记, 之后是基于 ~ 距离 的单词配对 。 我们在八种类型不同的语言上实验了 标注细胞填充问题, 发现用相对简单的形态学语言, 其本身的正统性允许穿孔模型达到可尊重的准确性。 混合的地形和语系常规性可以缓解特别复杂的细胞- phonlogic 系统的困难 。 我们的结果表明, 手动制作许多标记的例子可能是不必要的努力。 然而, 需要做更多的工作, 以便处理很少使用的形式。