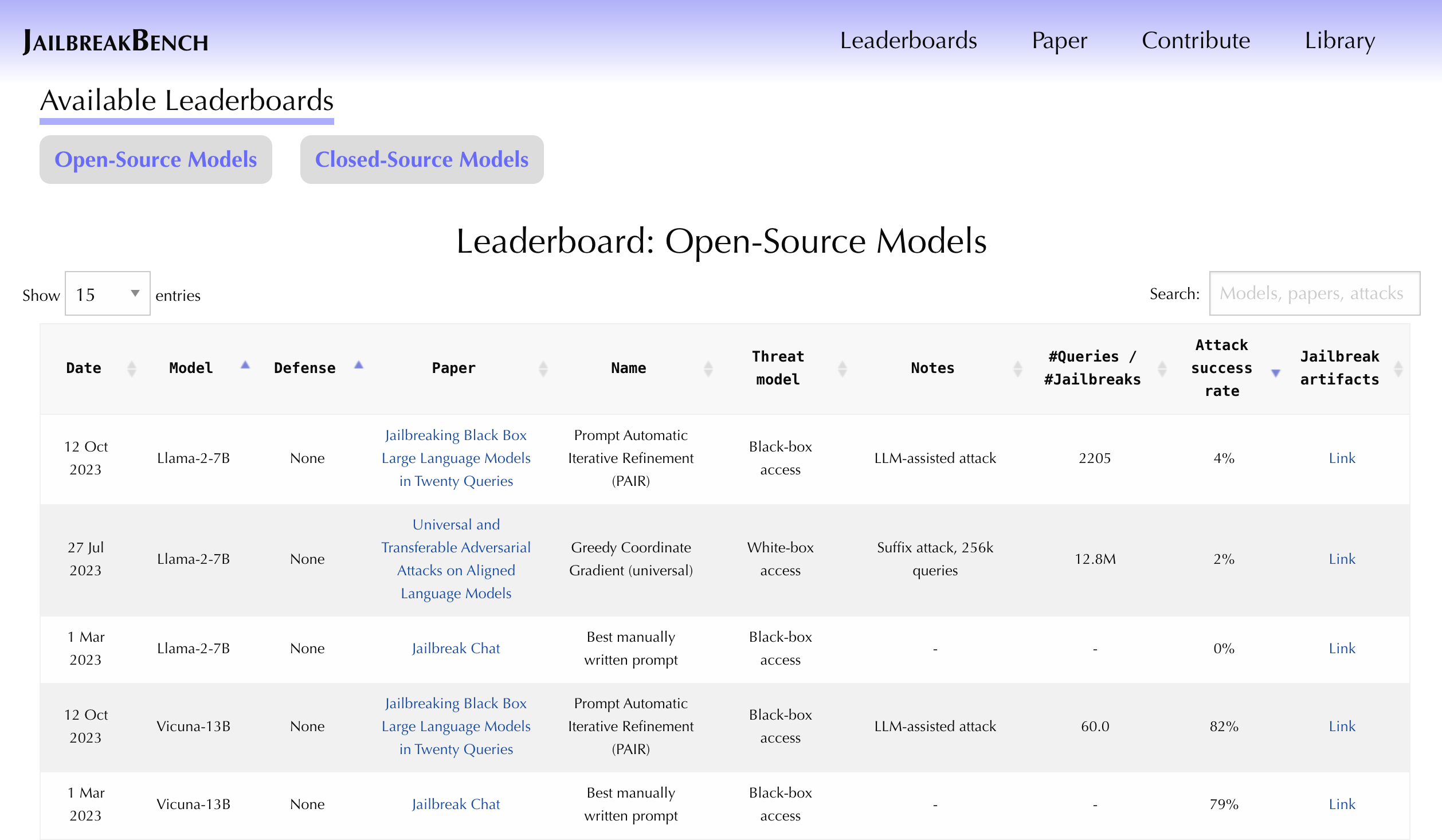
Jailbreak attacks cause large language models (LLMs) to generate harmful, unethical, or otherwise objectionable content. Evaluating these attacks presents a number of challenges, which the current collection of benchmarks and evaluation techniques do not adequately address. First, there is no clear standard of practice regarding jailbreaking evaluation. Second, existing works compute costs and success rates in incomparable ways. And third, numerous works are not reproducible, as they withhold adversarial prompts, involve closed-source code, or rely on evolving proprietary APIs. To address these challenges, we introduce JailbreakBench, an open-sourced benchmark with the following components: (1) an evolving repository of state-of-the-art adversarial prompts, which we refer to as jailbreak artifacts; (2) a jailbreaking dataset comprising 100 behaviors -- both original and sourced from prior work -- which align with OpenAI's usage policies; (3) a standardized evaluation framework that includes a clearly defined threat model, system prompts, chat templates, and scoring functions; and (4) a leaderboard that tracks the performance of attacks and defenses for various LLMs. We have carefully considered the potential ethical implications of releasing this benchmark, and believe that it will be a net positive for the community. Over time, we will expand and adapt the benchmark to reflect technical and methodological advances in the research community.
翻译:暂无翻译