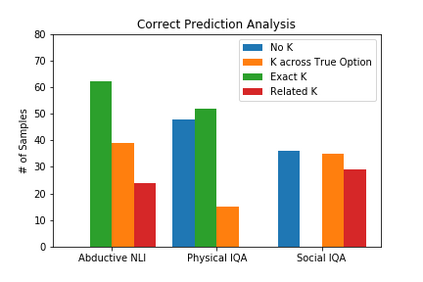
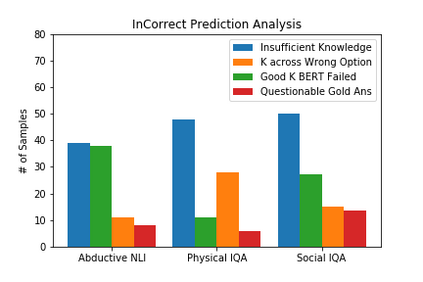
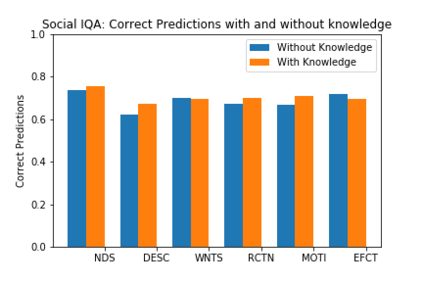
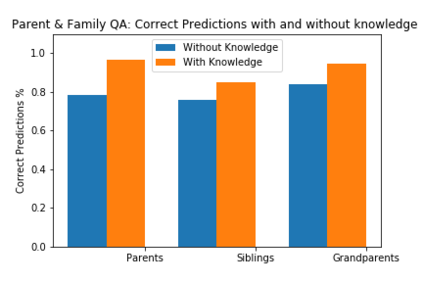
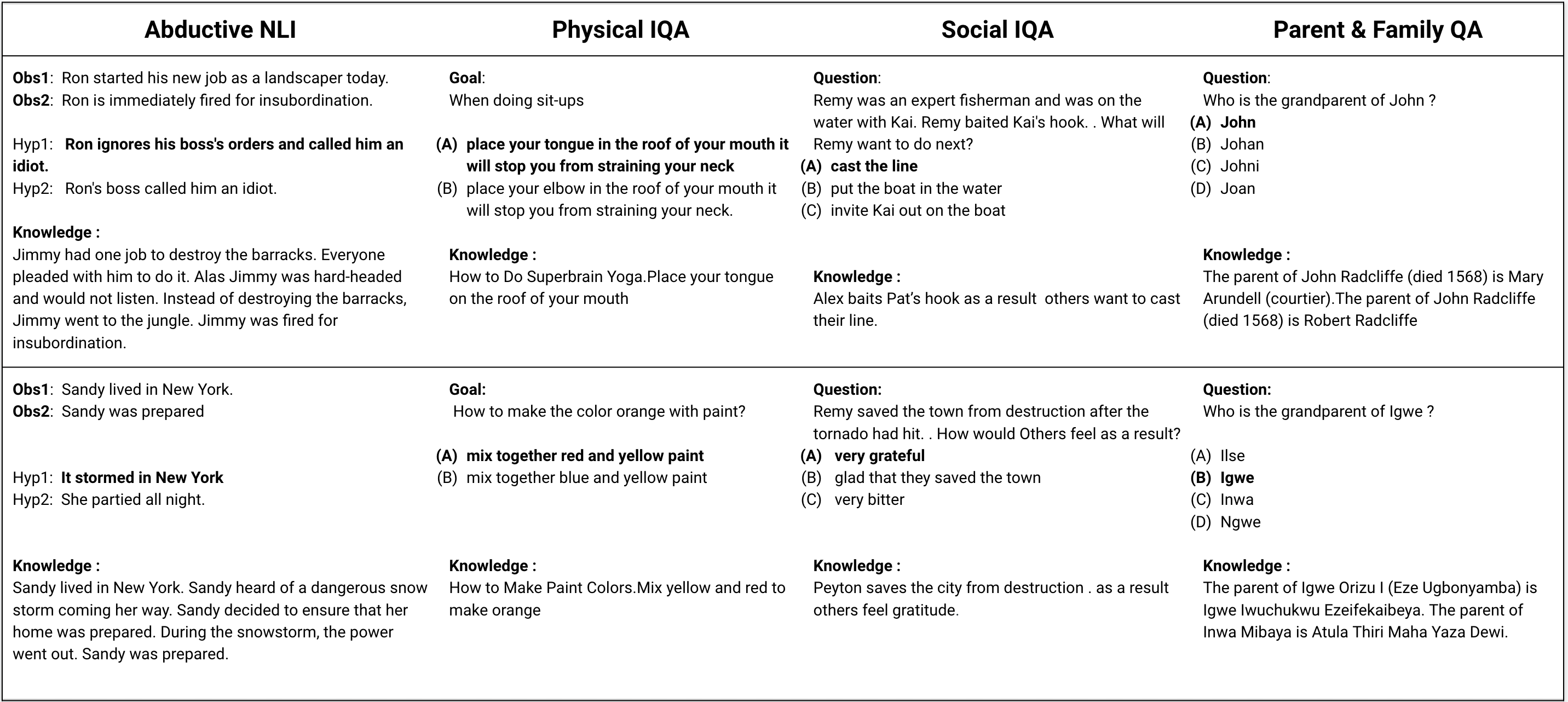
DARPA and Allen AI have proposed a collection of datasets to encourage research in Question Answering domains where (commonsense) knowledge is expected to play an important role. Recent language models such as BERT and GPT that have been pre-trained on Wikipedia articles and books, have shown decent performance with little fine-tuning on several such Multiple Choice Question-Answering (MCQ) datasets. Our goal in this work is to develop methods to incorporate additional (commonsense) knowledge into language model based approaches for better question answering in such domains. In this work we first identify external knowledge sources, and show that the performance further improves when a set of facts retrieved through IR is prepended to each MCQ question during both training and test phase. We then explore if the performance can be further improved by providing task specific knowledge in different manners or by employing different strategies for using the available knowledge. We present three different modes of passing knowledge and five different models of using knowledge including the standard BERT MCQ model. We also propose a novel architecture to deal with situations where information to answer the MCQ question is scattered over multiple knowledge sentences. We take 200 predictions from each of our best models and analyze how often the given knowledge is useful, how many times the given knowledge is useful but system failed to use it and some other metrices to see the scope of further improvements.
翻译:DARPA和Allen AI建议收集数据集,以鼓励在预期(常识)知识将发挥重要作用的问答领域进行研究。最近的一些语言模型,如BERT和GPT,在维基百科文章和书本上经过预先培训后,在几个多选择问题解答(MCQ)数据集方面表现良好,几乎没有微调。我们这项工作的目标是制定方法,将更多(常识)知识纳入基于语言的模型方法,以便在这类领域更好地回答问题。我们在此工作中首先确定外部知识来源,并表明,在培训和测试阶段,通过IRR检索的一套事实预先针对每个MCQ问题,业绩将进一步提高。然后我们探讨,通过以不同方式提供具体任务知识或采用不同战略利用现有知识,能否进一步改进业绩。我们提出了三种传递知识的不同模式和五种不同模式,包括标准的BERT MCQ模型。我们还提出了一个新的架构,用以处理信息如何回答通过IMQ检索的一套事实,但每次对MRCQ问题的分析往往会分散到多种知识的范围。我们探索了多少次的系统,如何利用其他知识的改进。我们采取了三种方法来分析其他方法。