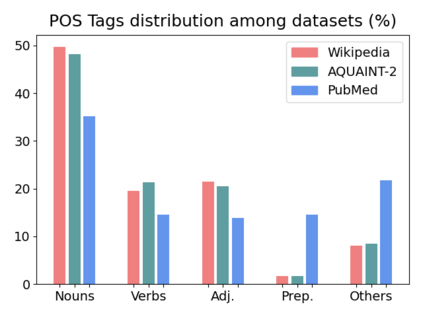
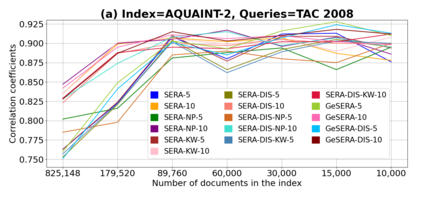
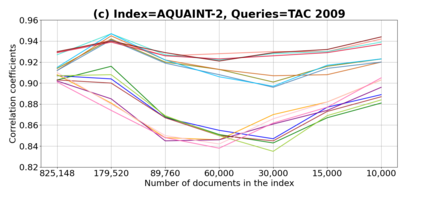
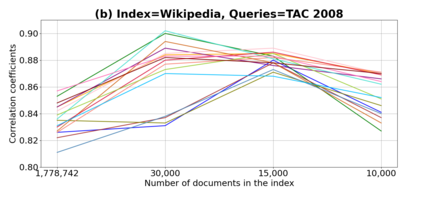
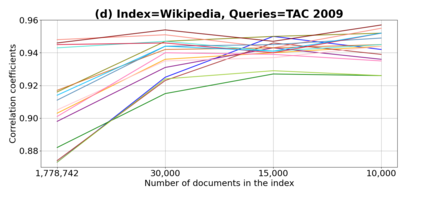
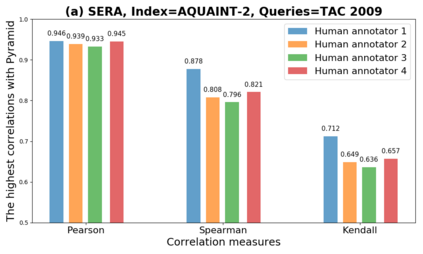
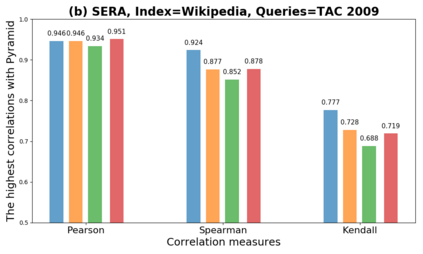
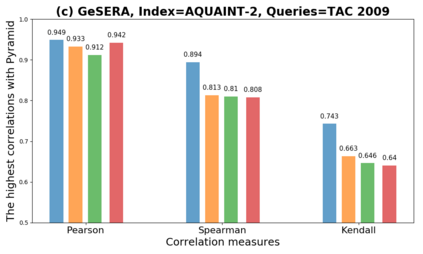
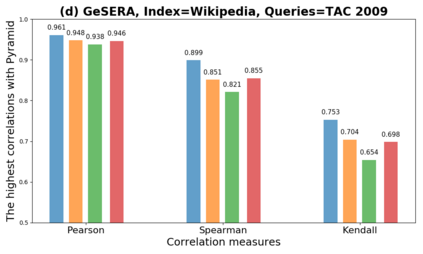
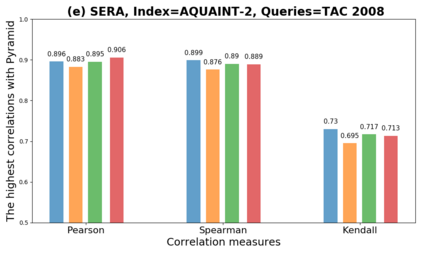
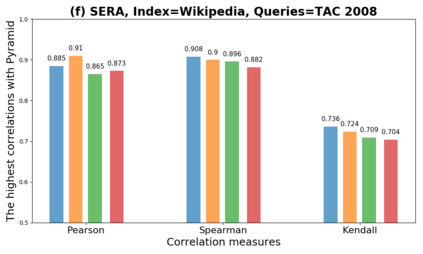
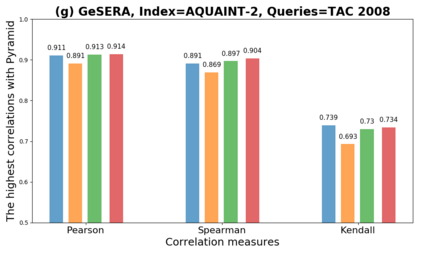
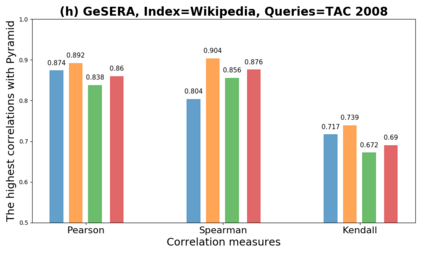
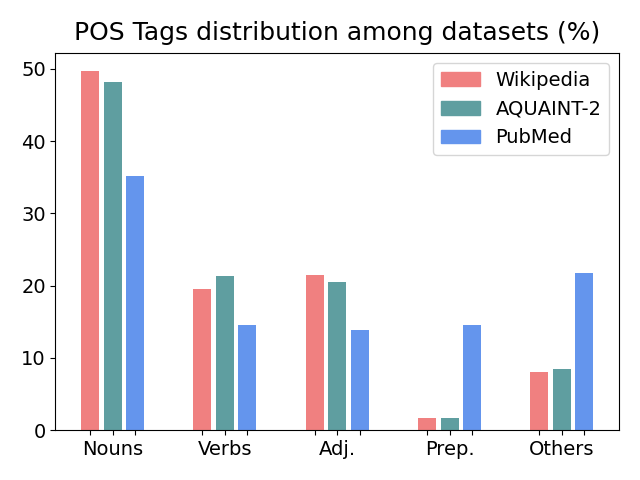
We present GeSERA, an open-source improved version of SERA for evaluating automatic extractive and abstractive summaries from the general domain. SERA is based on a search engine that compares candidate and reference summaries (called queries) against an information retrieval document base (called index). SERA was originally designed for the biomedical domain only, where it showed a better correlation with manual methods than the widely used lexical-based ROUGE method. In this paper, we take out SERA from the biomedical domain to the general one by adapting its content-based method to successfully evaluate summaries from the general domain. First, we improve the query reformulation strategy with POS Tags analysis of general-domain corpora. Second, we replace the biomedical index used in SERA with two article collections from AQUAINT-2 and Wikipedia. We conduct experiments with TAC2008, TAC2009, and CNNDM datasets. Results show that, in most cases, GeSERA achieves higher correlations with manual evaluation methods than SERA, while it reduces its gap with ROUGE for general-domain summary evaluation. GeSERA even surpasses ROUGE in two cases of TAC2009. Finally, we conduct extensive experiments and provide a comprehensive study of the impact of human annotators and the index size on summary evaluation with SERA and GeSERA.
翻译:我们介绍GeserA,这是用于评估一般领域自动采掘和抽象摘要的开放源码改进版SEA,SERA基于一个搜索引擎,根据信息检索文件库(称为索引)比较候选和参考摘要(所谓的查询),SERA最初只为生物医学领域设计,与广泛使用的基于词汇的ROUGE方法相比,它显示与人工方法的关联性更高。在本文中,我们通过调整基于内容的方法,从生物医学领域从生物医学领域向普通领域推广,以成功评价一般领域的摘要。首先,我们改进了对一般领域公司进行POS标记分析的查询重新制定战略。第二,我们用AQUAINT-2和Wikipedia的两篇文章收藏取代SERA使用的生物医学索引。我们与TAC2008、TAC2009和CNNDM数据集进行了实验。结果显示,在大多数情况下,Gesera与手工评估方法的关联性高于SERA,同时缩小了与ROUGE在一般领域评估方面的差距。GERA对TERA和SENA的两次全面评价和SERA的模型和SERA进行了我们对SERA的大规模评估。最后提供了一项关于SERA和SERA的实验。