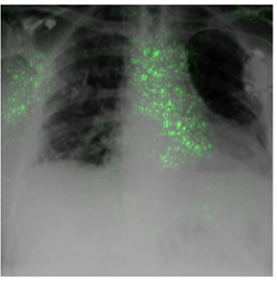
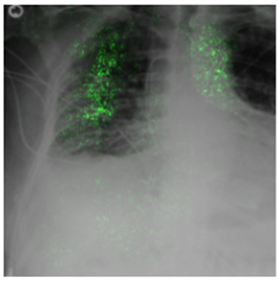
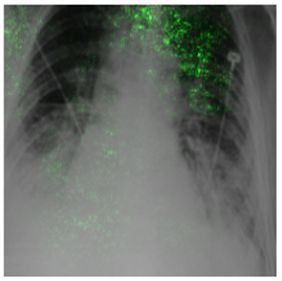
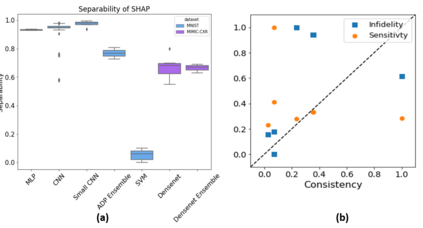
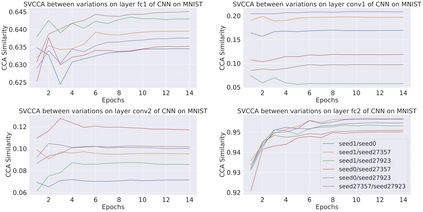
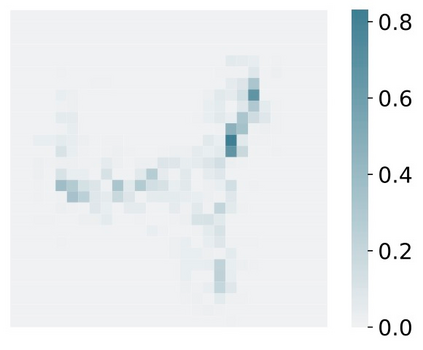
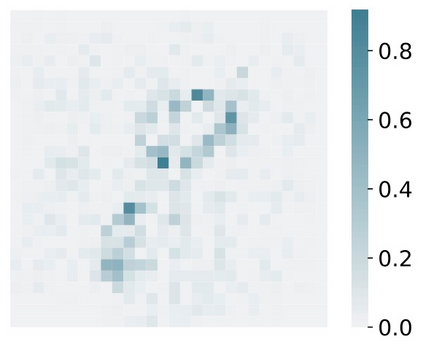
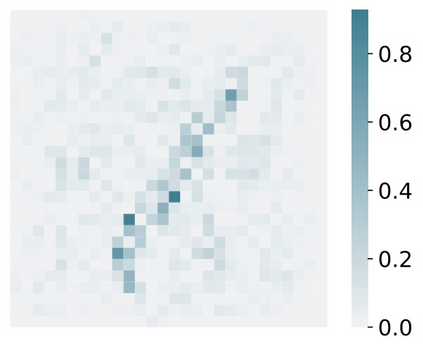
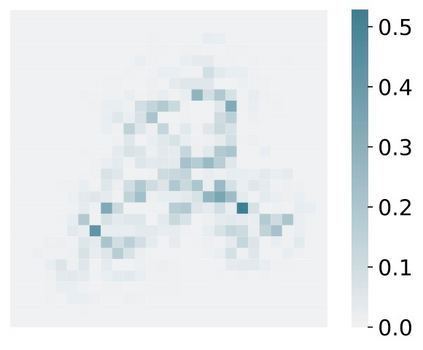
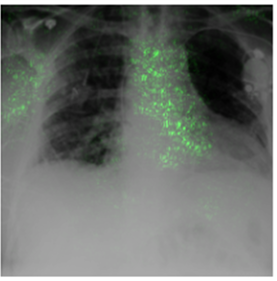
Deep Learning of neural networks has progressively become more prominent in healthcare with models reaching, or even surpassing, expert accuracy levels. However, these success stories are tainted by concerning reports on the lack of model transparency and bias against some medical conditions or patients' sub-groups. Explainable methods are considered the gateway to alleviate many of these concerns. In this study we demonstrate that the generated explanations are volatile to changes in model training that are perpendicular to the classification task and model structure. This raises further questions about trust in deep learning models for healthcare. Mainly, whether the models capture underlying causal links in the data or just rely on spurious correlations that are made visible via explanation methods. We demonstrate that the output of explainability methods on deep neural networks can vary significantly by changes of hyper-parameters, such as the random seed or how the training set is shuffled. We introduce a measure of explanation consistency which we use to highlight the identified problems on the MIMIC-CXR dataset. We find explanations of identical models but with different training setups have a low consistency: $\approx$ 33% on average. On the contrary, kernel methods are robust against any orthogonal changes, with explanation consistency at 94%. We conclude that current trends in model explanation are not sufficient to mitigate the risks of deploying models in real life healthcare applications.
翻译:心血管网络的深度学习在医疗保健中越来越突出,模型达到甚至超过专家准确性水平。然而,这些成功事例因缺乏模型透明度和偏向某些医疗条件或病人子群的报告而受到影响。可以解释的方法被视为缓解许多这类关切的网关。在这项研究中,我们证明,所产生的解释对于与分类任务和模型结构相适应的模型培训的变化是变化不定的。这提出了对深入学习保健模型的信任的进一步问题。主要是,这些模型是否在数据中捕捉潜在的因果联系,还是仅仅依赖通过解释方法可见的虚假相关性。我们表明,深神经网络解释方法的输出可能因超参数的变化而大不相同,例如随机种子或训练组合如何被打乱。我们用一种解释一致性的尺度来突出MIMIC-CXR数据集中已查明的问题。我们找到对相同模型的解释,但不同的培训设置却不够一致:平均为$\approx33%。我们证明,在深层神经网络中解释方法的输出会因超常数而有很大差异,例如随机的种子或训练组合组合式解释。我们对于当前的部署模式来说,对于任何稳定性解释是没有强性解释。在真正的解释。在真正的保健模型中,对于正确的解释。