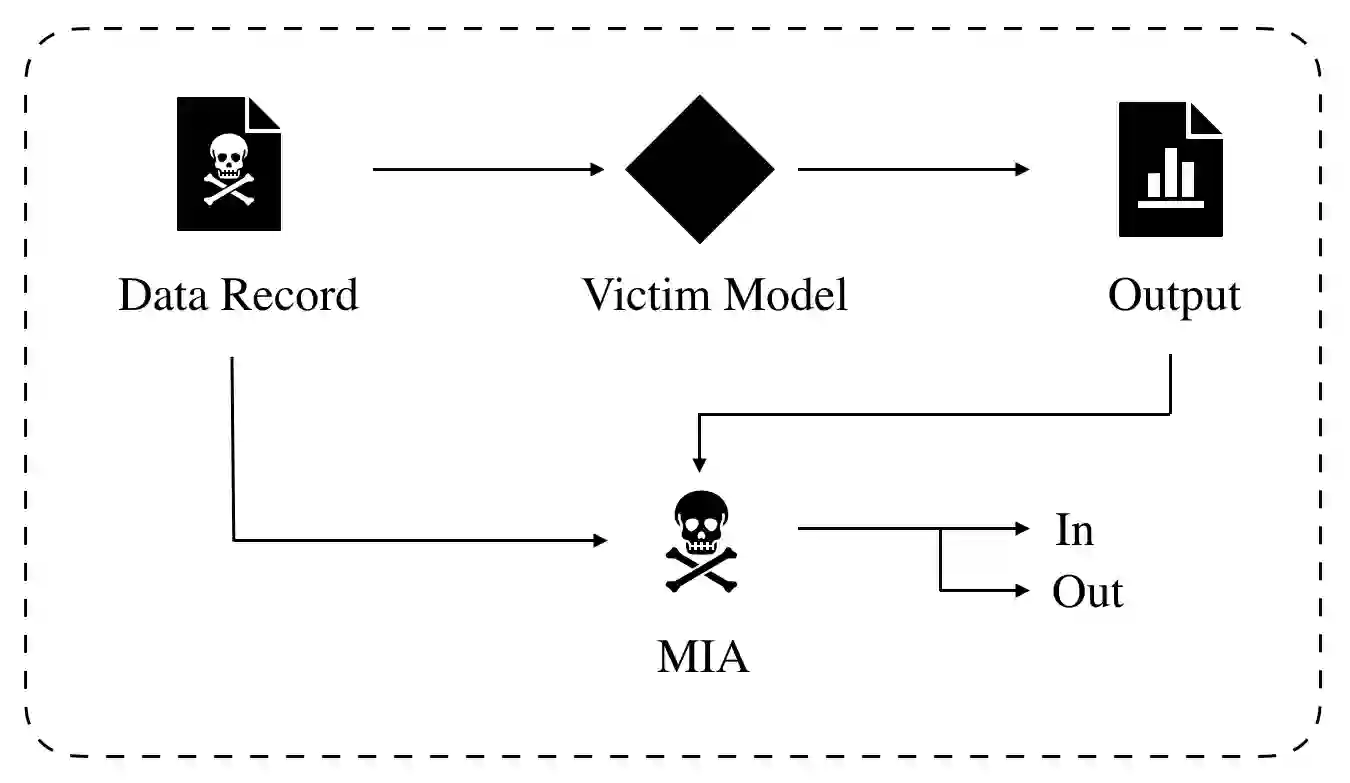
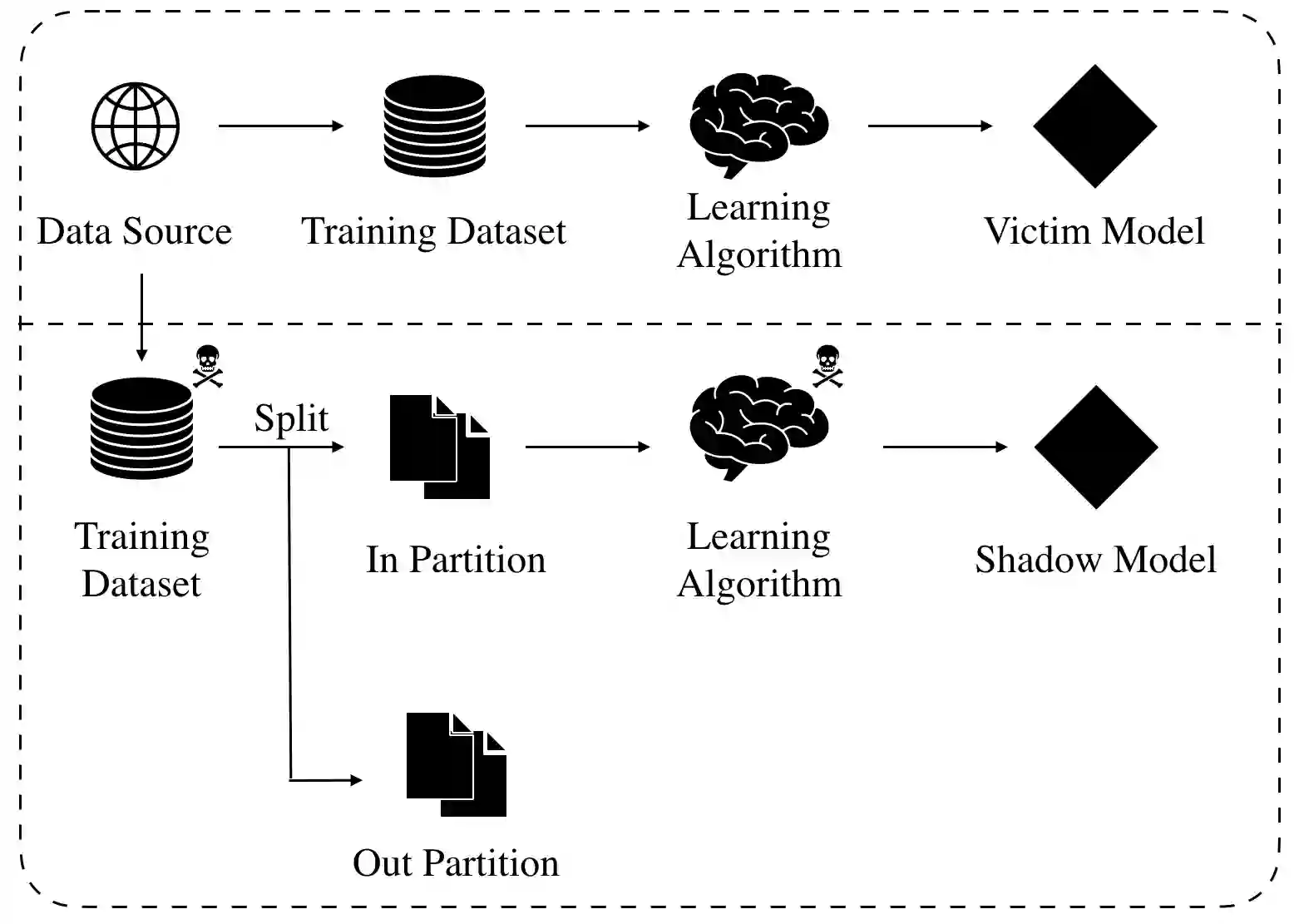
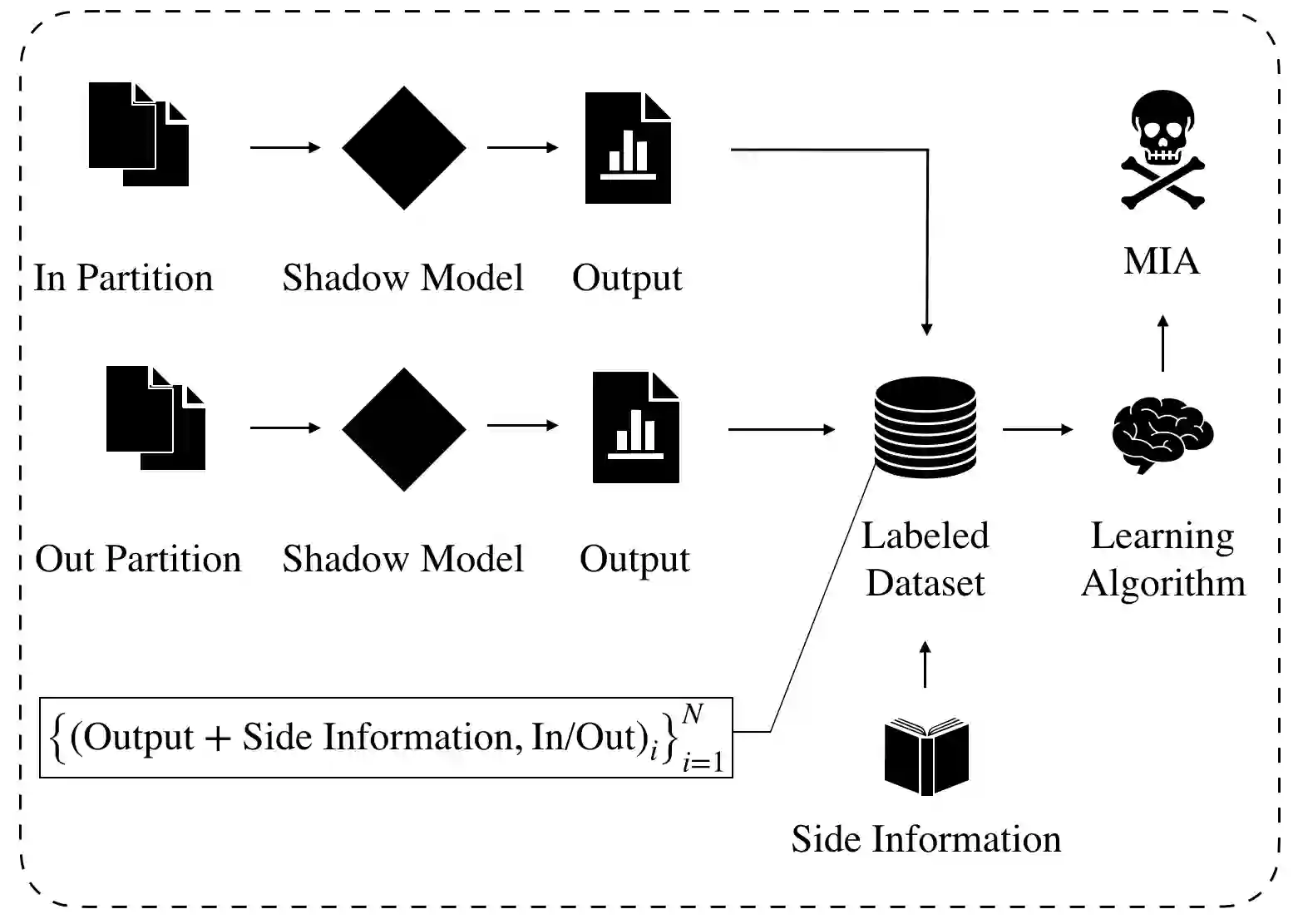
We study the privacy implications of training recurrent neural networks (RNNs) with sensitive training datasets. Considering membership inference attacks (MIAs), which aim to infer whether or not specific data records have been used in training a given machine learning model, we provide empirical evidence that a neural network's architecture impacts its vulnerability to MIAs. In particular, we demonstrate that RNNs are subject to a higher attack accuracy than feed-forward neural network (FFNN) counterparts. Additionally, we study the effectiveness of two prominent mitigation methods for preempting MIAs, namely weight regularization and differential privacy. For the former, we empirically demonstrate that RNNs may only benefit from weight regularization marginally as opposed to FFNNs. For the latter, we find that enforcing differential privacy through either of the following two methods leads to a less favorable privacy-utility trade-off in RNNs than alternative FFNNs: (i) adding Gaussian noise to the gradients calculated during training as a part of the so-called DP-SGD algorithm and (ii) adding Gaussian noise to the trainable parameters as a part of a post-training mechanism that we propose. As a result, RNNs can also be less amenable to mitigation methods, bringing us to the conclusion that the privacy risks pertaining to the recurrent architecture are higher than the feed-forward counterparts.
翻译:我们研究了培训具有敏感培训数据集的经常性神经网络的隐私影响。考虑到成员推论攻击(MIAs)旨在推断特定数据记录是否用于培训某个机器学习模型,我们提供了经验证据,证明神经网络的建筑结构影响其易受MIA的伤害。我们特别表明,与Feed-for-for-nal网络(FFNN)对口单位相比, RNNNs的进攻性交易准确度要低一些。此外,我们研究了两项防止MIA的显著缓解方法的有效性,即体重调整和差别隐私。对于前者,我们的经验表明,RNPs可能只受益于比FFNes略微的重量规范化。对于后者,我们发现通过以下两种方法中的两种方法之一强制实施差异隐私,导致RNPs在RNs上的隐私使用权宜性交易减少。 (i)在培训过程中计算出的梯度中加上高调音,作为所谓的DP-SGD算法的一部分;以及(ii)在经常性结构中增加高调的RSAsian噪音,作为我们可接受的保密性标准的一部分。