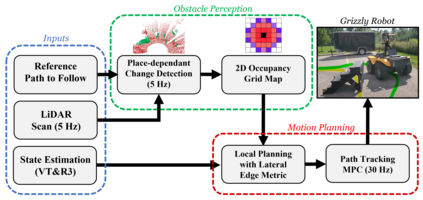
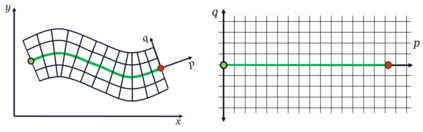
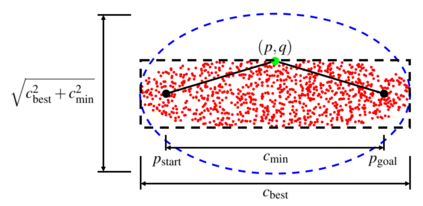
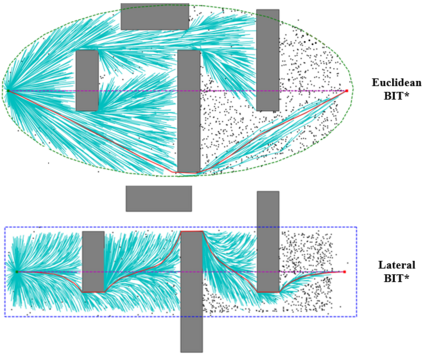
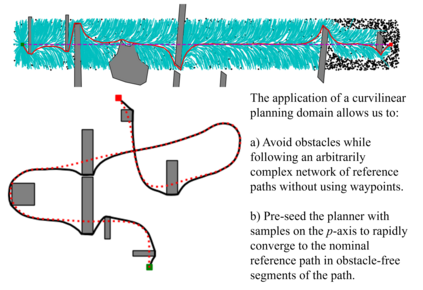
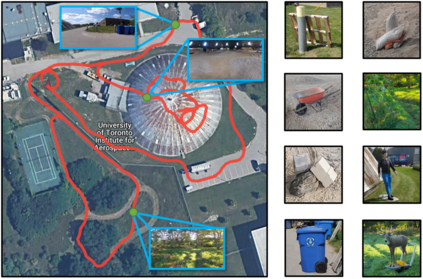
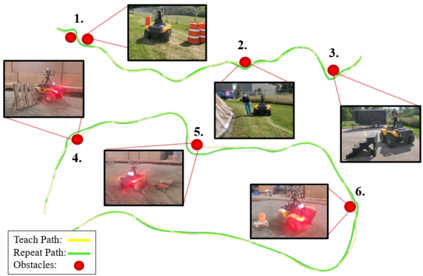
Visual Teach and Repeat 3 (VT&R3), a generalization of stereo VT&R, achieves long-term autonomous path-following using topometric mapping and localization from a single rich sensor stream. In this paper, we improve the capabilities of a LiDAR implementation of VT&R3 to reliably detect and avoid obstacles in changing environments. Our architecture simplifies the obstacle-perception problem to that of place-dependent change detection. We then extend the behaviour of generic sample-based motion planners to better suit the teach-and-repeat problem structure by introducing a new edge-cost metric paired with a curvilinear planning space. The resulting planner generates naturally smooth paths that avoid local obstacles while minimizing lateral path deviation to best exploit prior terrain knowledge. While we use the method with VT&R, it can be generalized to suit arbitrary path-following applications. Experimental results from online run-time analysis, unit testing, and qualitative experiments on a differential drive robot show the promise of the technique for reliable long-term autonomous operation in complex unstructured environments.
翻译:视觉教学和重复3 (VT & R3) 立体VT&R3 通用的立体VT&R, 利用从单一的丰富传感器流进行测量绘图和定位,实现长期自主路径。 在本文中, 我们提高LiDAR实施VT & R3 的能力, 以可靠地探测和避免变化环境中的障碍。 我们的架构将障碍感知问题简化到以地点为依存的变化检测。 然后, 我们推广通用抽样运动规划者的行为, 以更好地适应教学和重复问题结构, 引入一个新的边价衡量标准, 与卷轴规划空间相配。 由此产生的规划器会产生自然的顺畅路径, 避免本地障碍, 同时尽量减少横向路径偏差, 以最佳的方式利用先前的地形知识。 虽然我们使用VT & R 的方法, 它可以被推广到任意的路径跟踪应用。 在线运行时间分析、 单位测试和对差异驱动机器人的定性实验结果显示了在复杂无结构环境中进行可靠长期自主操作的技术的前景 。