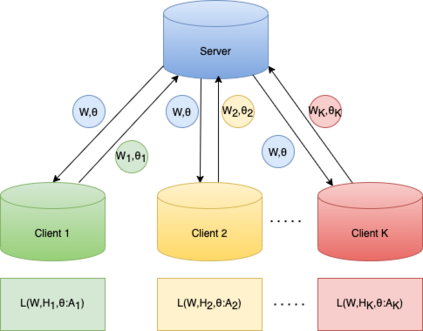
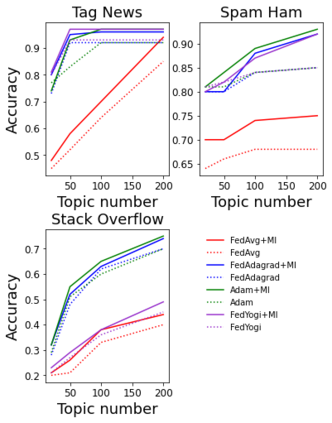
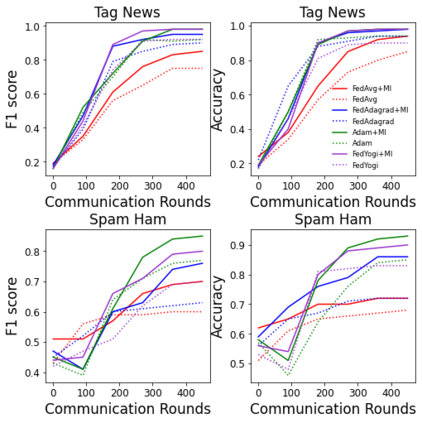
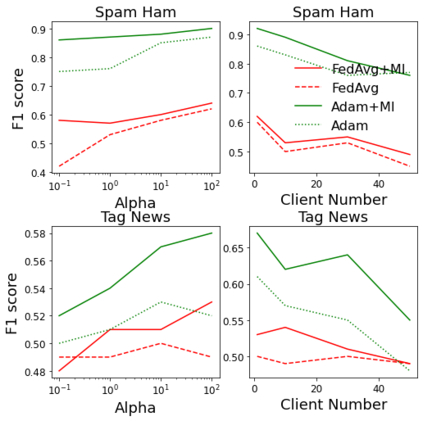
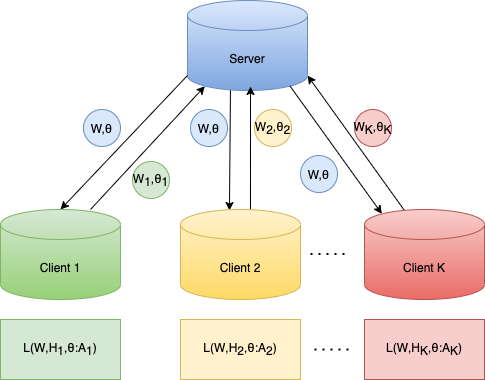
Non-negative matrix factorization (NMF) based topic modeling is widely used in natural language processing (NLP) to uncover hidden topics of short text documents. Usually, training a high-quality topic model requires large amount of textual data. In many real-world scenarios, customer textual data should be private and sensitive, precluding uploading to data centers. This paper proposes a Federated NMF (FedNMF) framework, which allows multiple clients to collaboratively train a high-quality NMF based topic model with locally stored data. However, standard federated learning will significantly undermine the performance of topic models in downstream tasks (e.g., text classification) when the data distribution over clients is heterogeneous. To alleviate this issue, we further propose FedNMF+MI, which simultaneously maximizes the mutual information (MI) between the count features of local texts and their topic weight vectors to mitigate the performance degradation. Experimental results show that our FedNMF+MI methods outperform Federated Latent Dirichlet Allocation (FedLDA) and the FedNMF without MI methods for short texts by a significant margin on both coherence score and classification F1 score.
翻译:以非负矩阵因子化(NMF)为基础的专题模型被广泛用于自然语言处理(NLP),以发现短文本文件的隐藏专题。通常,培训高质量专题模型需要大量文本数据。在许多现实世界情景中,客户文本数据应是私有和敏感的,不得上传到数据中心。本文件提议了一个基于非负矩阵因子化(FedNMF)框架,使多个客户能够利用当地储存的数据对基于高质量NMF的专题模型进行协作培训。然而,标准联合学习将大大削弱下游任务专题模型(例如文本分类)的性能,因为客户的数据分布各不相同。为了缓解这一问题,我们进一步提议FedNMF+MI,同时将本地文本的计算特征与其主题重量载体之间的相互信息最大化,以缓解性能退化。实验结果表明,我们的FDNMF+MI方法在一致性和分类F1的分数1之间,以显著的差幅超过FedNMMF方法。