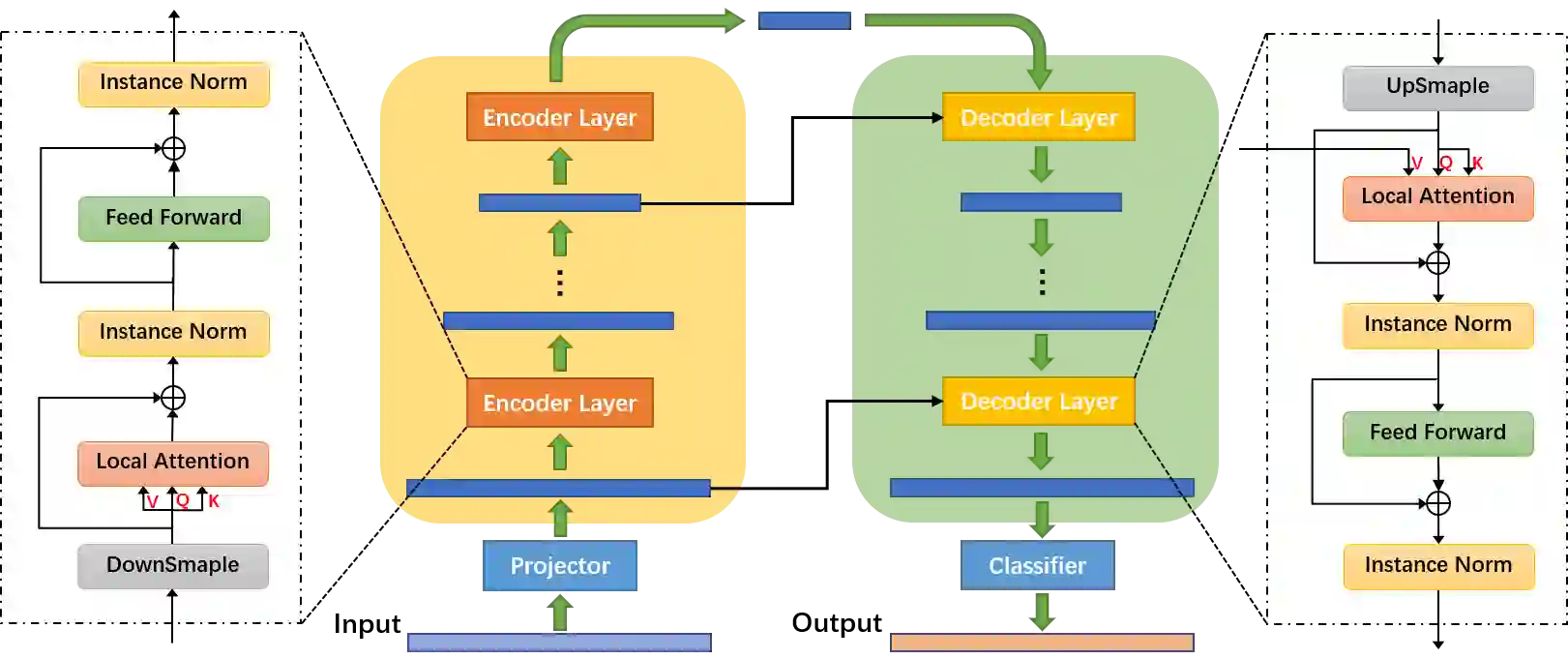
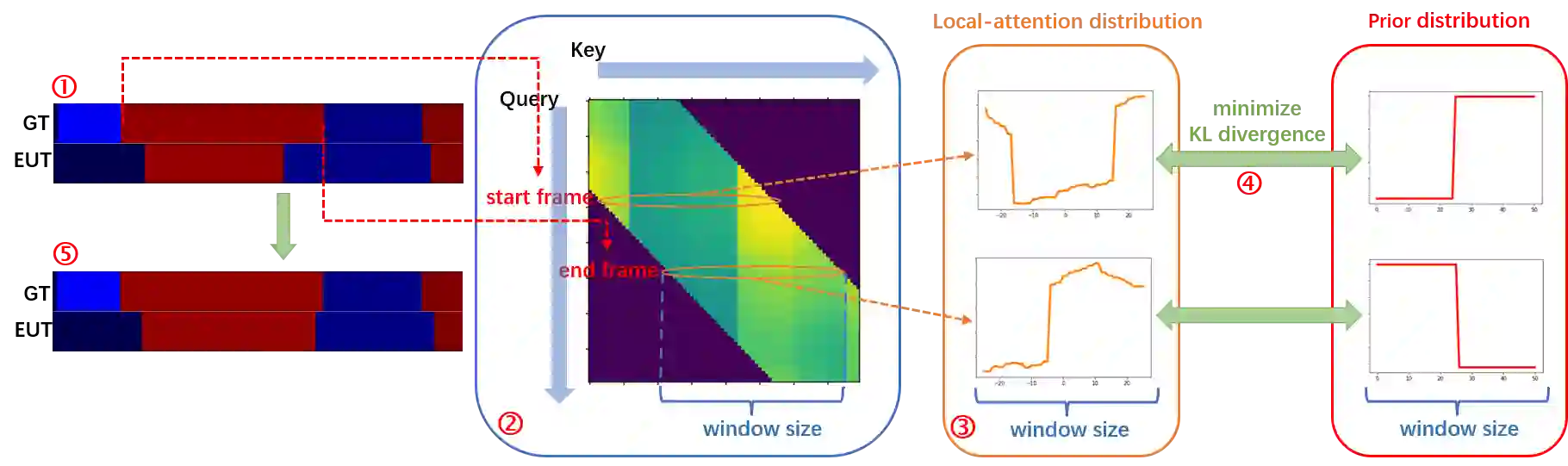
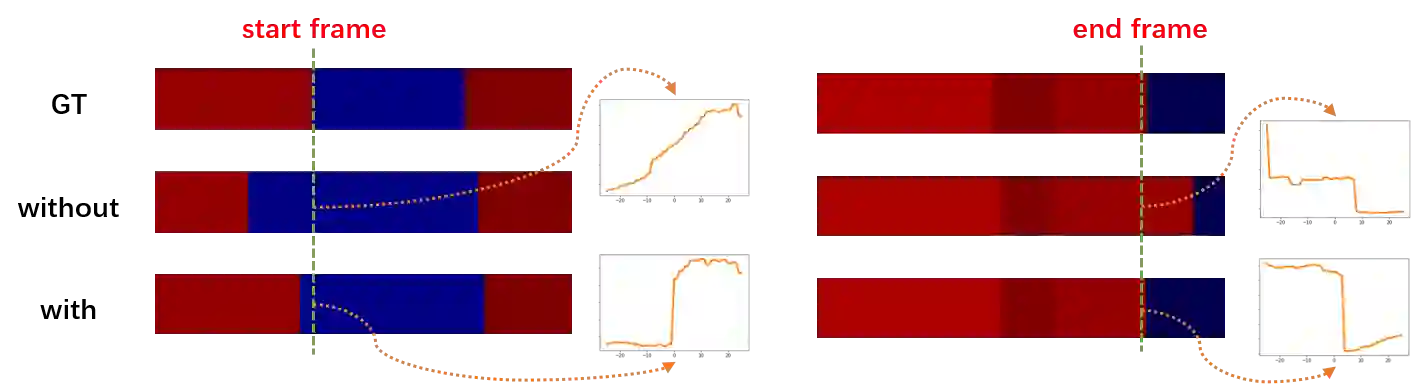
Action classification has made great progress, but segmenting and recognizing actions from long untrimmed videos remains a challenging problem. Most state-of-the-art methods focus on designing temporal convolution-based models, but the limitations on modeling long-term temporal dependencies and inflexibility of temporal convolutions limit the potential of these models. Recently, Transformer-based models with flexible and strong sequence modeling ability have been applied in various tasks. However, the lack of inductive bias and the inefficiency of handling long video sequences limit the application of Transformer in action segmentation. In this paper, we design a pure Transformer-based model without temporal convolutions by incorporating the U-Net architecture. The U-Transformer architecture reduces complexity while introducing an inductive bias that adjacent frames are more likely to belong to the same class, but the introduction of coarse resolutions results in the misclassification of boundaries. We observe that the similarity distribution between a boundary frame and its neighboring frames depends on whether the boundary frame is the start or end of an action segment. Therefore, we further propose a boundary-aware loss based on the distribution of similarity scores between frames from attention modules to enhance the ability to recognize boundaries. Extensive experiments show the effectiveness of our model.
翻译:行动分类取得了很大进展,但长期未剪辑的视频片段的分解和识别行动仍是一个棘手的问题。大多数最先进的方法侧重于设计基于时间革命的模型,但模型的长期时间依赖性和时间演变不灵活性的限制限制了这些模型的潜力。最近,在各种任务中应用了具有灵活和强力序列建模能力的基于变异器的模型。然而,缺乏感知偏差和处理长视频序列的效率不高,限制了变异器在动作分割中的应用。在本文中,我们设计了一个纯粹的基于变异器的模型,而没有时间变化的模型,纳入了U-Net结构。U-变异结构降低了复杂性,同时引入了一种隐性偏差,即相邻的框架更有可能属于同一类别,但引入粗化的分辨率导致边界分类错误。我们发现,边界框架及其相邻框架之间的相似性分布取决于边界框架是行动段的开始还是结束。因此,我们进一步建议根据我们相似的模型模型模型的分布来降低复杂性,从而提高我们从相似的分数框架之间的分界线。