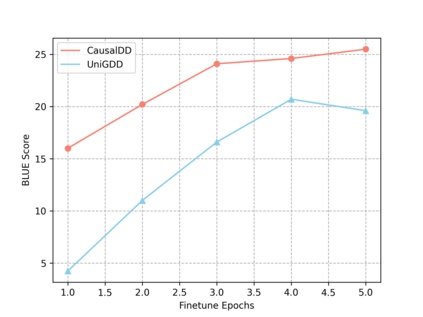
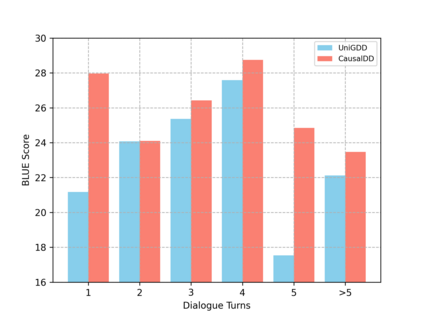
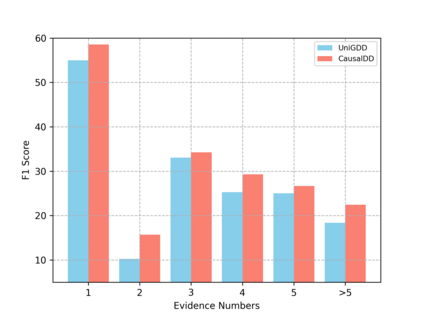
The goal of document-grounded dialogue (DocGD) is to generate a response by grounding the evidence in a supporting document in accordance with the dialogue context. This process involves four variables that are causally connected. Recently, task-specific pre-training has greatly boosted performances on many downstream tasks. Existing DocGD methods, however, continue to rely on general pre-trained language models without a specifically tailored pre-training approach that explicitly captures the causal relationships. To tackle this issue, we are the first to present a causally-complete dataset construction strategy for building million-level DocGD pre-training corpora. To better capture causality, we further propose a causally-perturbed pre-training strategy, which introduces causal perturbations on the variables and optimizes the overall causal effect. Experiments on three benchmark datasets demonstrate that our causal pre-training achieves considerable and consistent improvements under fully-supervised, low-resource, few-shot, and zero-shot settings.
翻译:暂无翻译