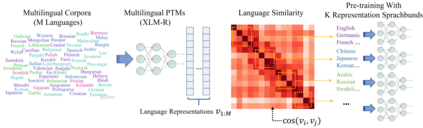
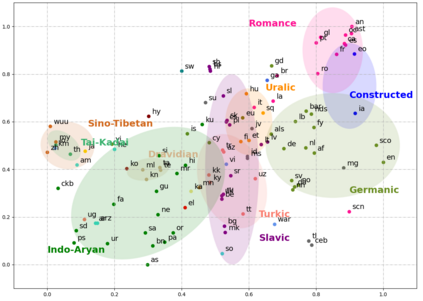
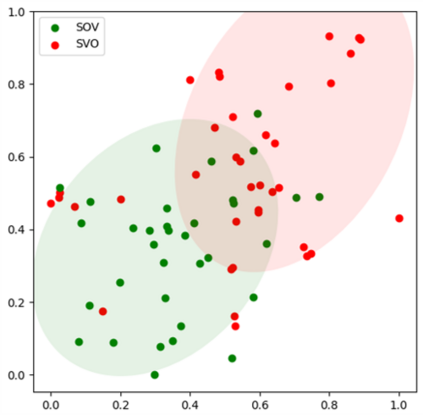
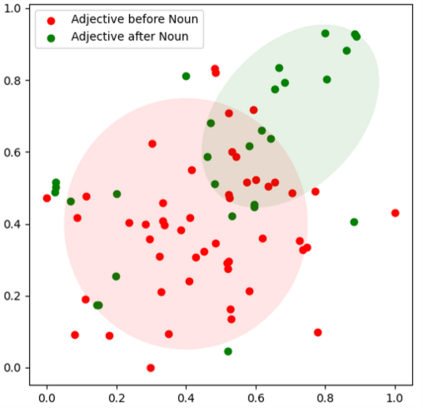
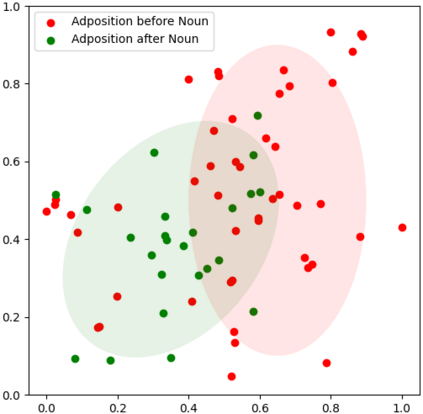
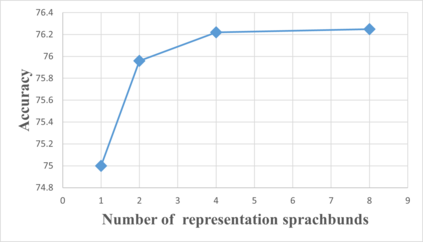
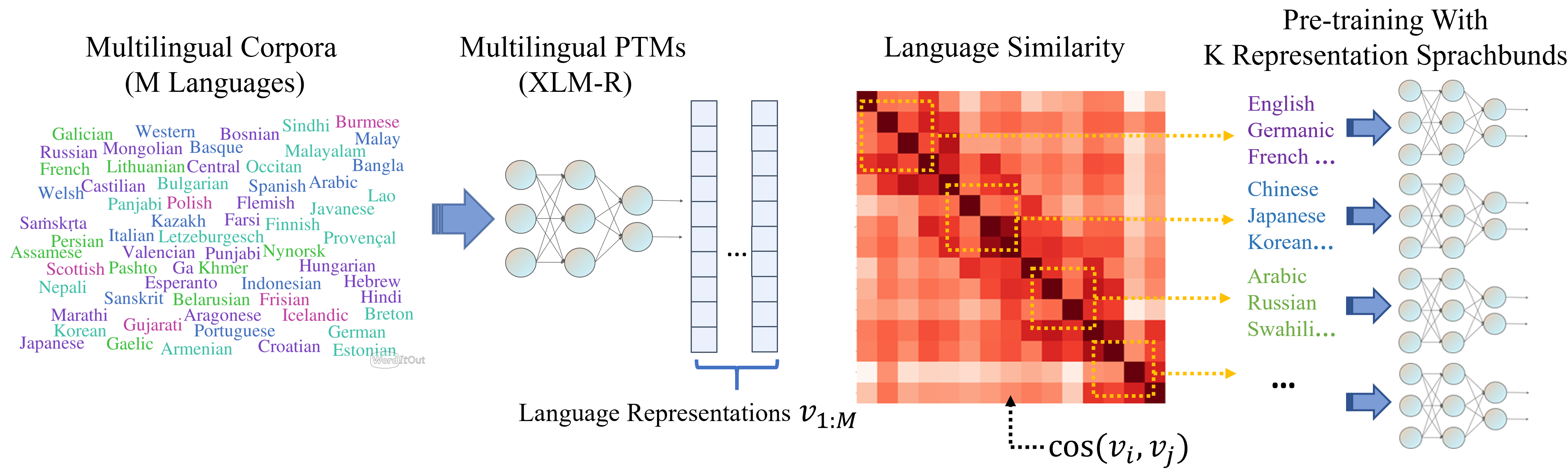
Multilingual pre-trained models have demonstrated their effectiveness in many multilingual NLP tasks and enabled zero-shot or few-shot transfer from high-resource languages to low resource ones. However, due to significant typological differences and contradictions between some languages, such models usually perform poorly on many languages and cross-lingual settings, which shows the difficulty of learning a single model to handle massive diverse languages well at the same time. To alleviate this issue, we present a new multilingual pre-training pipeline. We propose to generate language representation from multilingual pre-trained models and conduct linguistic analysis to show that language representation similarity reflect linguistic similarity from multiple perspectives, including language family, geographical sprachbund, lexicostatistics and syntax. Then we cluster all the target languages into multiple groups and name each group as a representation sprachbund. Thus, languages in the same representation sprachbund are supposed to boost each other in both pre-training and fine-tuning as they share rich linguistic similarity. We pre-train one multilingual model for each representation sprachbund. Experiments are conducted on cross-lingual benchmarks and significant improvements are achieved compared to strong baselines.
翻译:多语言预先培训模式在许多多语种国家语言方案任务中显示了其有效性,并使得从高资源语言向低资源语言的零点或微点转换成为了低资源语言,然而,由于某些语言之间的显著类型差异和矛盾,这些模式在许多语言和跨语言环境中通常表现不佳,这表明很难同时学习单一模式来处理大量多种语言。为了缓解这一问题,我们提出了一个新的多语言培训前编程。我们提议从多语言预先培训模式中产生语言代表,并进行语言分析,以表明语言代表的相似性反映了多种观点的语言相似性,包括语言家庭、地理学、词汇学和语法。然后,我们把所有目标语言集中到多个群体中,将每个群体命名为代表sprachbund。因此,同样代表的sprachbund语言在培训前和微调两方面都应该相互促进,因为它们具有丰富的语言相似性。我们为每个代表模式预先培训了一个多语言模式。我们进行了跨语种基准的实验,并实现了与强势基线的显著改进。