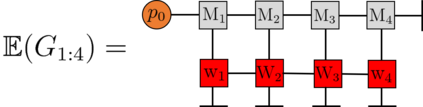
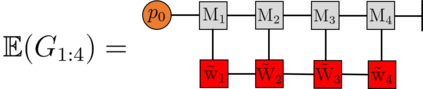
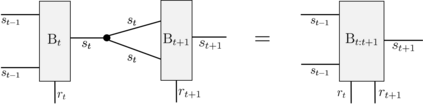
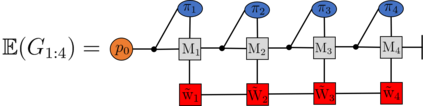
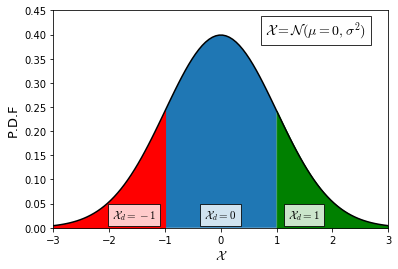
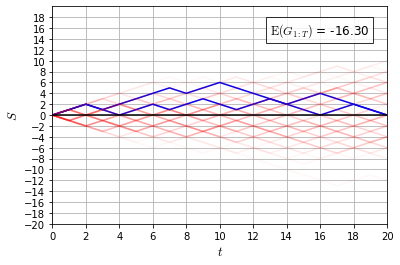
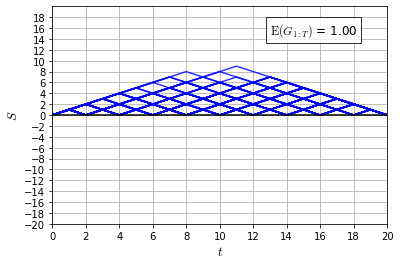
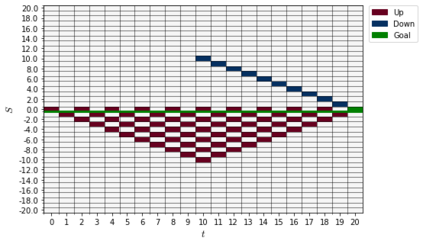
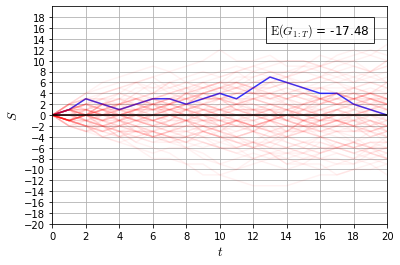
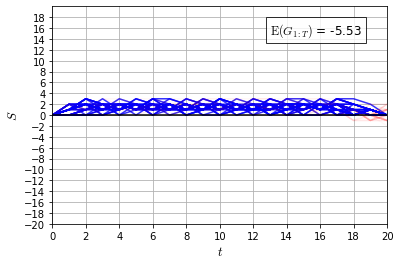
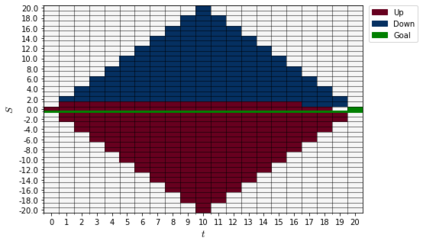
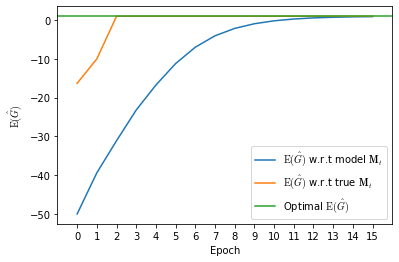
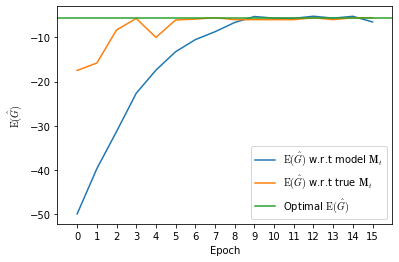
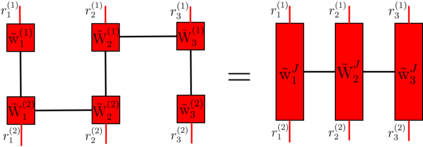
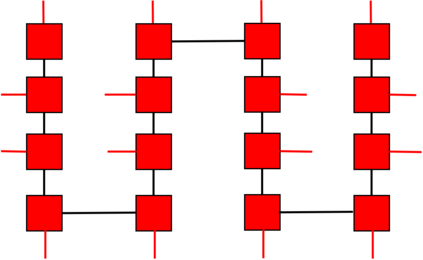
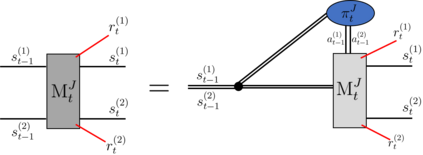
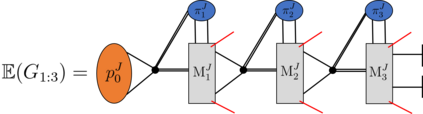
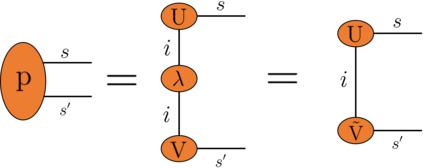
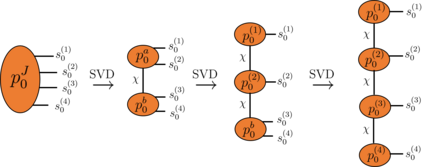
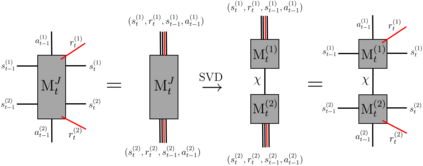
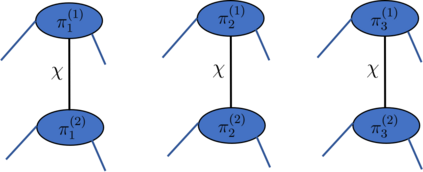
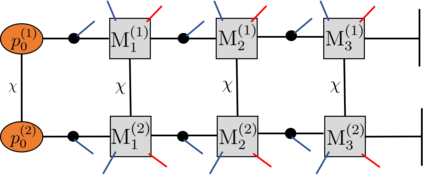
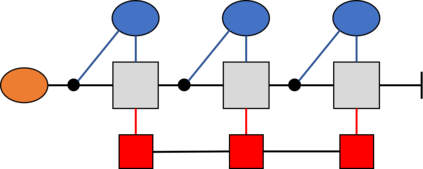
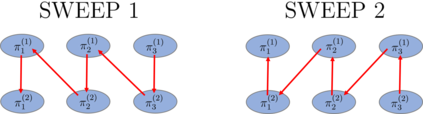
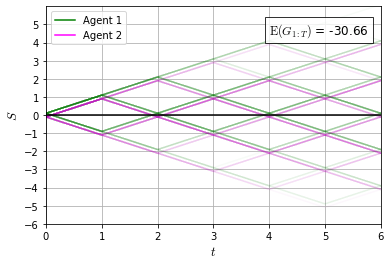
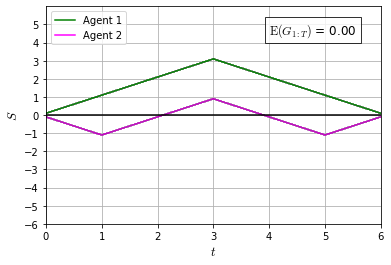
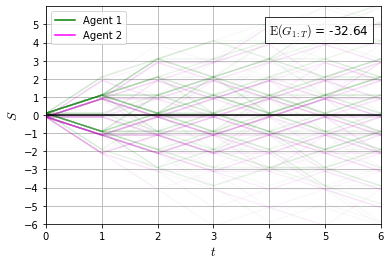
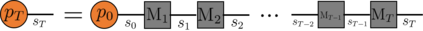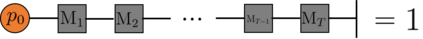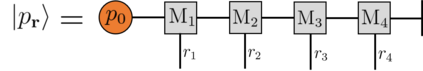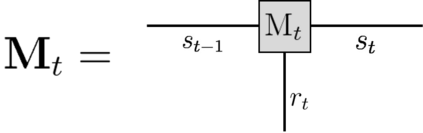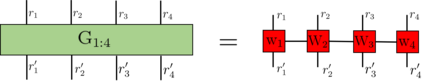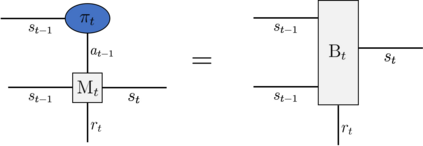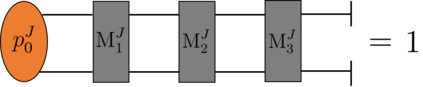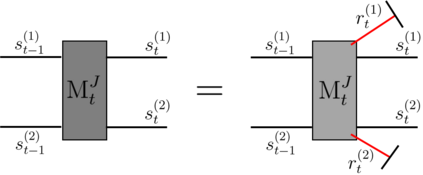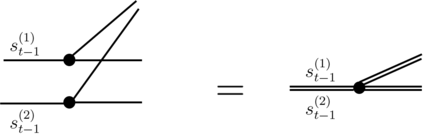Recently it has been shown that tensor networks (TNs) have the ability to represent the expected return of a single-agent finite Markov decision process (FMDP). The TN represents a distribution model, where all possible trajectories are considered. When extending these ideas to a multi-agent setting, distribution models suffer from the curse of dimensionality: the exponential relation between the number of possible trajectories and the number of agents. The key advantage of using TNs in this setting is that there exists a large number of established optimisation and decomposition techniques that are specific to TNs, that one can apply to ensure the most efficient representation is found. In this report, these methods are used to form a TN that represents the expected return of a multi-agent reinforcement learning (MARL) task. This model is then applied to a 2 agent random walker example, where it was shown that the policy is correctly optimised using a DMRG technique. Finally, I demonstrate the use of an exact decomposition technique, reducing the number of elements in the tensors by 97.5%, without experiencing any loss of information.
翻译:暂无翻译