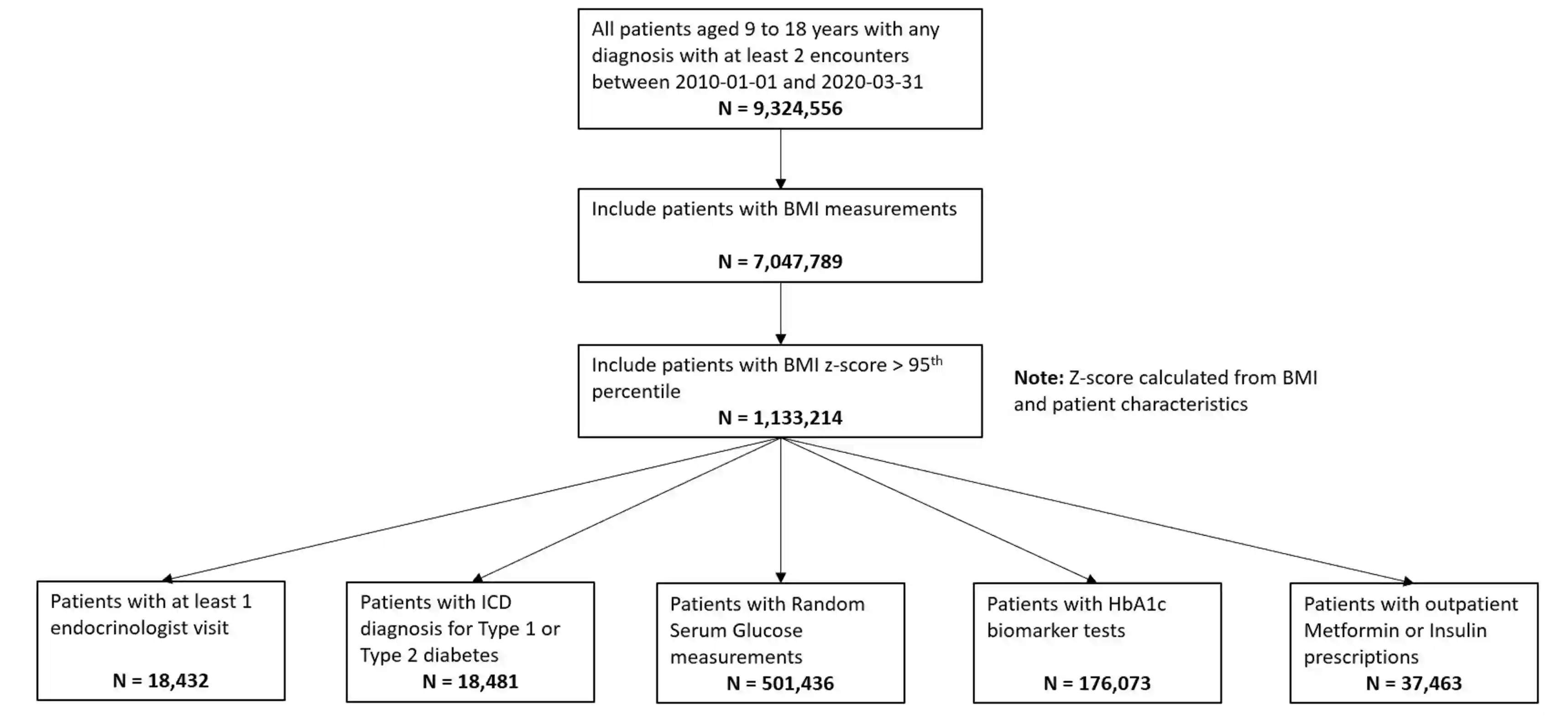
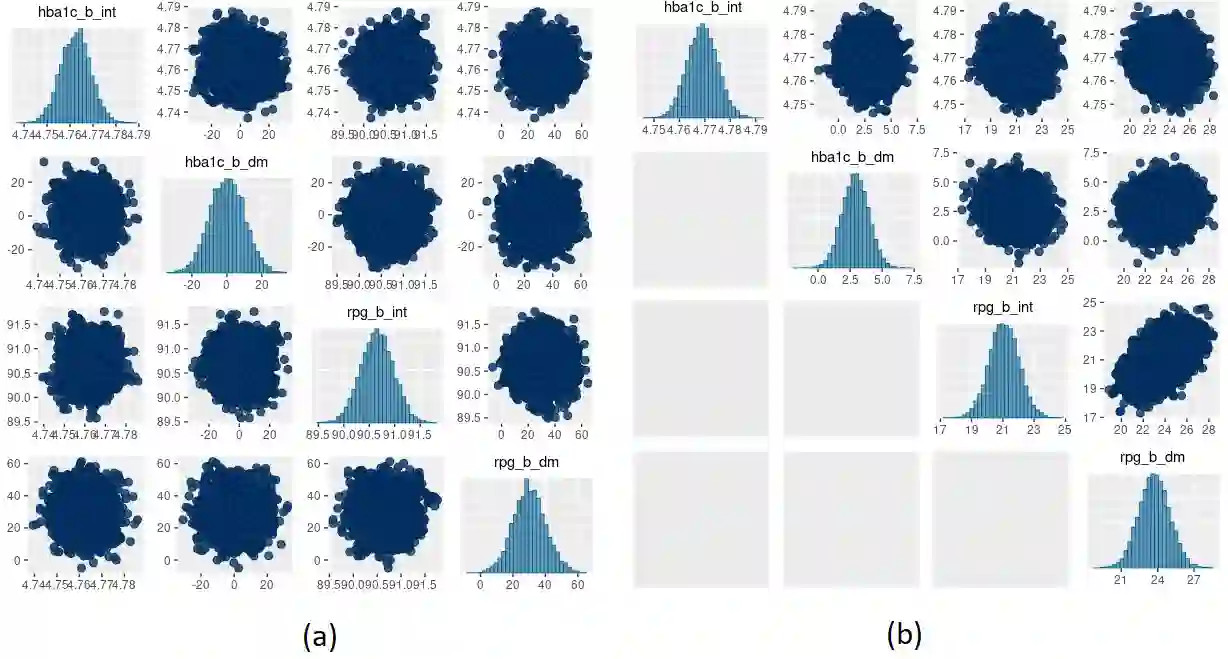
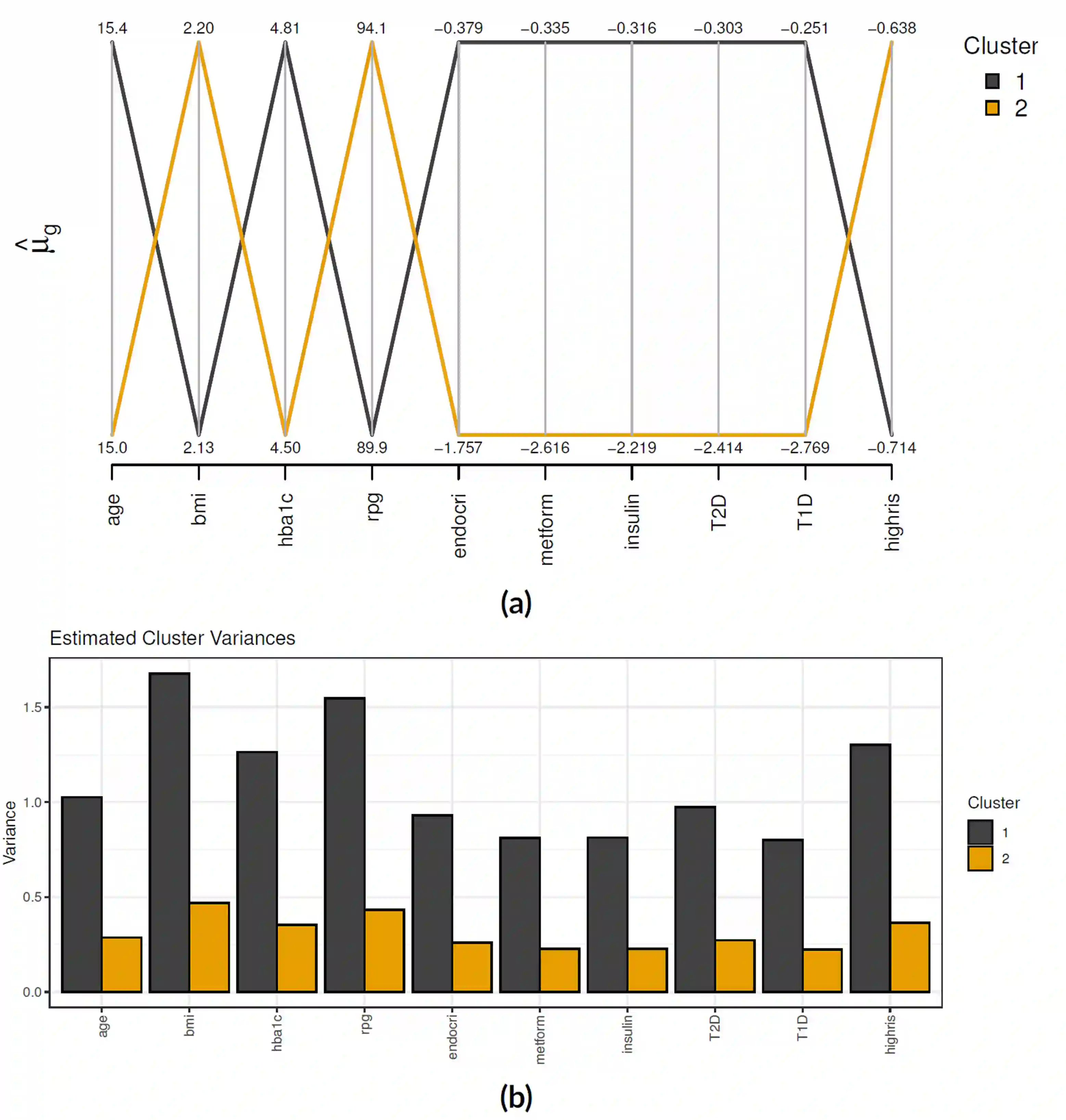
Bayesian approaches to clinical analyses for the purposes of patient phenotyping have been limited by the computational challenges associated with applying the Markov-Chain Monte-Carlo (MCMC) approach to large real-world data. Approximate Bayesian inference via optimization of the variational evidence lower bound, often called Variational Bayes (VB), has been successfully demonstrated for other applications. We investigate the performance and characteristics of currently available R and Python VB software for variational Bayesian Latent Class Analysis (LCA) of realistically large real-world observational data. We used a real-world data set, OptumTM electronic health records (EHR), containing pediatric patients with risk indicators for type 2 diabetes mellitus that is a rare form in pediatric patients. The aim of this work is to validate a Bayesian patient phenotyping model for generality and extensibility and crucially that it can be applied to a realistically large real-world clinical data set. We find currently available automatic VB methods are very sensitive to initial starting conditions, model definition, algorithm hyperparameters and choice of gradient optimiser. The Bayesian LCA model was challenging to implement using VB but we achieved reasonable results with very good computational performance compared to MCMC.
翻译:临床分析的贝叶斯方法用于患者表型分型方面,其在应用马尔科夫-蒙特卡罗 (MCMC) 方法处理大型现实世界数据时,面临计算挑战。通过最优化变分证据下限来进行近似贝叶斯推断,通常称为变分贝叶斯 (VB),已成功地应用于其他应用领域。我们研究了当前可用的 R 和 Python VB 软件在大规模真实世界观察数据的变分贝叶斯潜类分析 (LCA) 中的性能和特点。我们使用 OptumTM 电子健康记录 (EHR) 的真实世界数据集,其中包含具有 2 型糖尿病风险指标的儿童患者,该糖尿病类型在儿童患者中非常罕见。本文旨在验证贝叶斯患者表型模型的普适性、可扩展性,以及其能够应用于真实世界临床数据集的重要性。我们发现当前可用的自动 VB 方法对初始起始条件、模型定义、算法超参数和梯度优化器的选择非常敏感。用 VB 实现贝叶斯 LCA 模型具有挑战性,但与 MCMC相比,我们取得了合理的结果,并具有非常良好的计算性能。