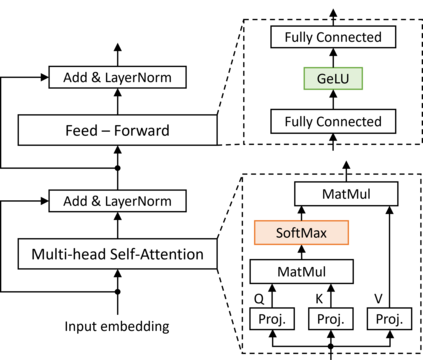
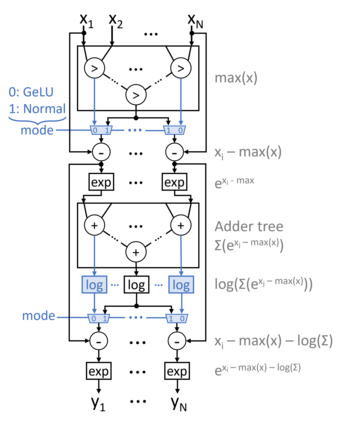
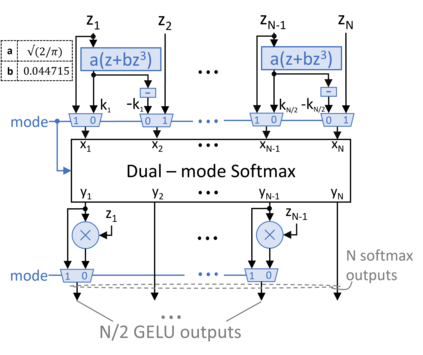
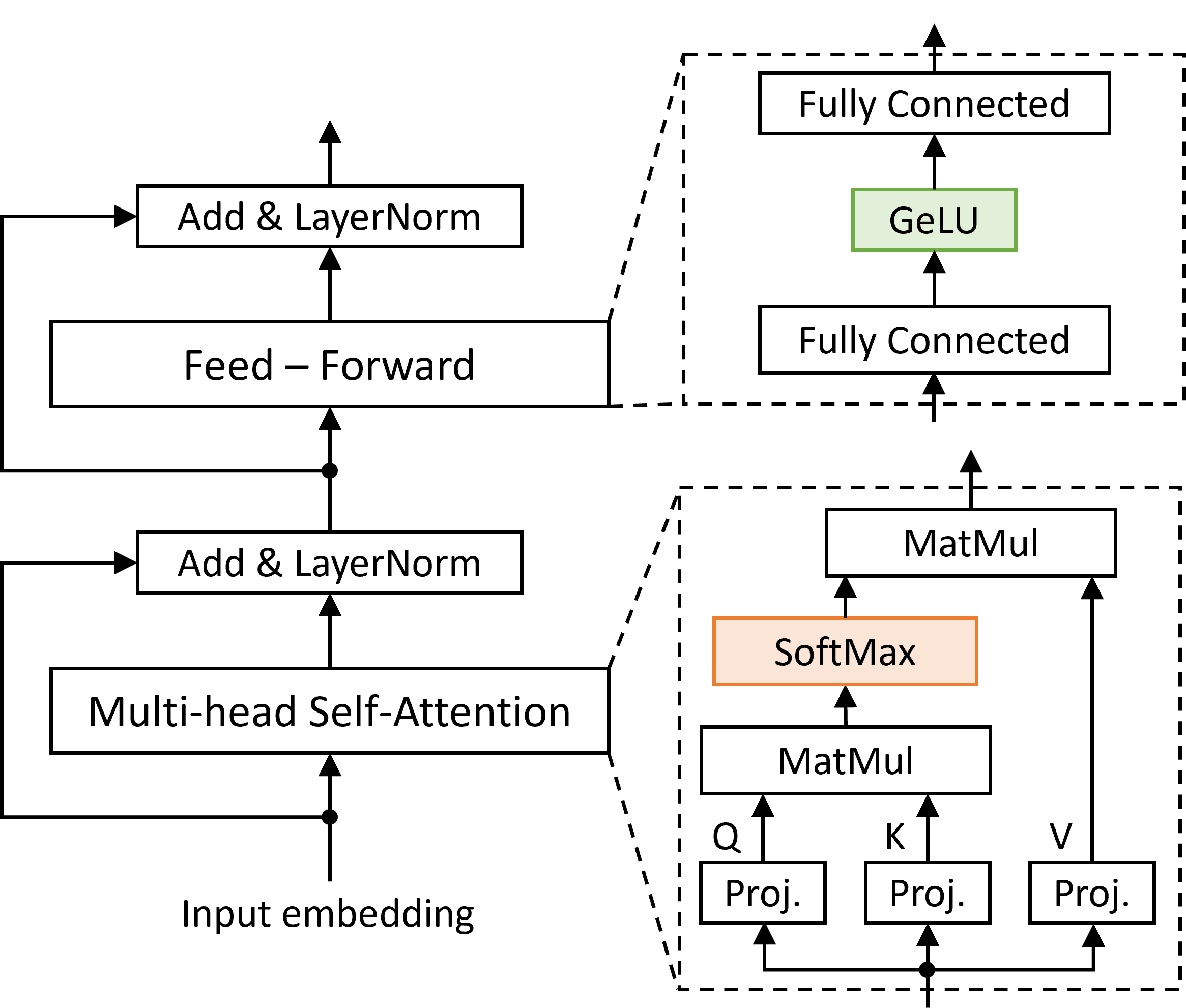
Transformers have improved drastically the performance of natural language processing (NLP) and computer vision applications. The computation of transformers involves matrix multiplications and non-linear activation functions such as softmax and GELU (Gaussion Error Linear Unit) that are accelerated directly in hardware. Currently, function evaluation is done separately for each function and rarely allows for hardware reuse. To mitigate this problem, in this work, we map the computation of GELU to a softmax operator. In this way, the efficient hardware units designed already for softmax can be reused for computing GELU as well. Computation of GELU can enjoy the inherent vectorized nature of softmax and produce in parallel multiple GELU outcomes. Experimental results show that computing GELU via a pre-existing and incrementally modified softmax hardware unit (a) does not reduce the accuracy of representative NLP applications and (b) allows the reduction of the overall hardware area and power by 6.1% and 11.9%, respectively, on average.
翻译:暂无翻译