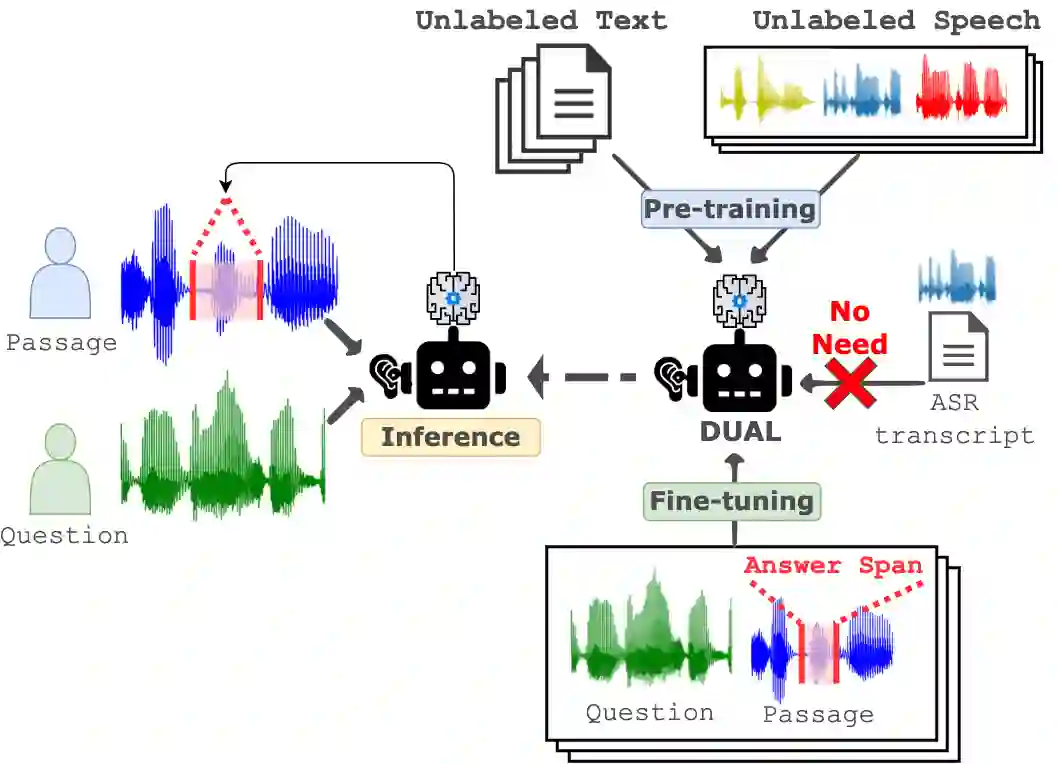
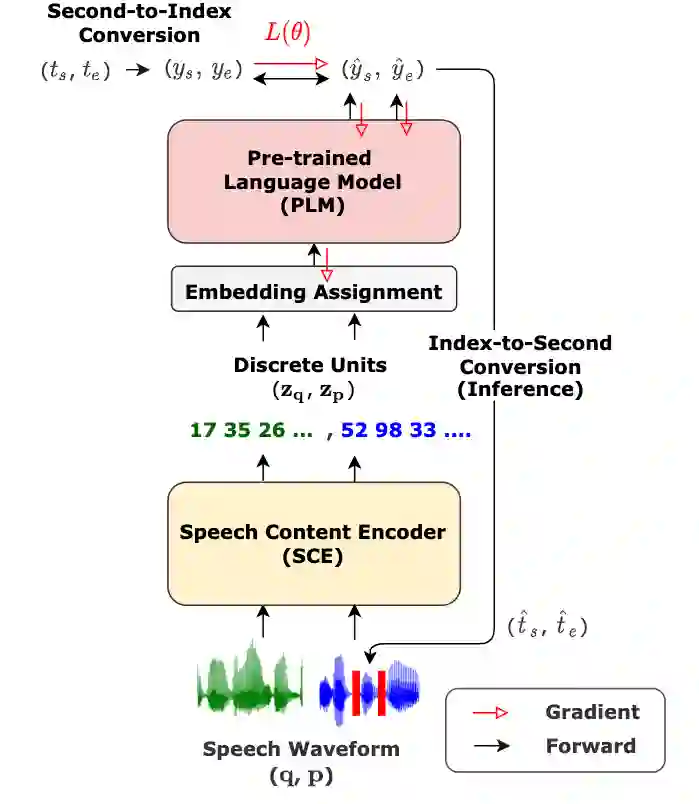
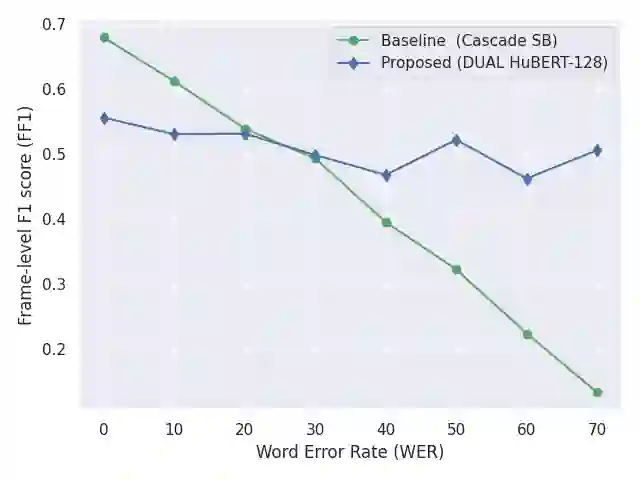
Spoken Question Answering (SQA) is to find the answer from a spoken document given a question, which is crucial for personal assistants when replying to the queries from the users. Existing SQA methods all rely on Automatic Speech Recognition (ASR) transcripts. Not only does ASR need to be trained with massive annotated data that are time and cost-prohibitive to collect for low-resourced languages, but more importantly, very often the answers to the questions include name entities or out-of-vocabulary words that cannot be recognized correctly. Also, ASR aims to minimize recognition errors equally over all words, including many function words irrelevant to the SQA task. Therefore, SQA without ASR transcripts (textless) is always highly desired, although known to be very difficult. This work proposes Discrete Spoken Unit Adaptive Learning (DUAL), leveraging unlabeled data for pre-training and fine-tuned by the SQA downstream task. The time intervals of spoken answers can be directly predicted from spoken documents. We also release a new SQA benchmark corpus, NMSQA, for data with more realistic scenarios. We empirically showed that DUAL yields results comparable to those obtained by cascading ASR and text QA model and robust to real-world data. Our code and model will be open-sourced.
翻译:口问解答(SQA)是指从口语文件中找到答案,这个问题对于个人助理在回答用户问询时至关重要,个人助理也至关重要。现有的SQA方法都依赖自动语音识别(ASR)记录誊本。不仅ASR需要用大量附加说明的数据来培训,这些数据需要时间和成本鼓励,以便收集低资源语言,更重要的是,对问题的答案往往包括名称实体或词汇外的词句,无法正确识别。此外,ASR还力求将所有字词的识别错误,包括许多与SQA任务无关的功能字眼,都尽可能减少。因此,SQA没有ASR记录(无文本)的SQA总是非常希望的,尽管人们知道这是非常困难的。这项工作提议使用隐名单位校对学习(DUfficult Spoken Unitictal Reformalation),将无标签的数据用于培训前和由SQA下游任务进行微调。口头回答的时间间隔可以从口述文件中直接预测。我们还发布了一个新的SQA基准、NMSQA模型、可比较的DQA模型,以我们真实的版本的数据展示。我们的DascialDal-A的版本显示的版本。