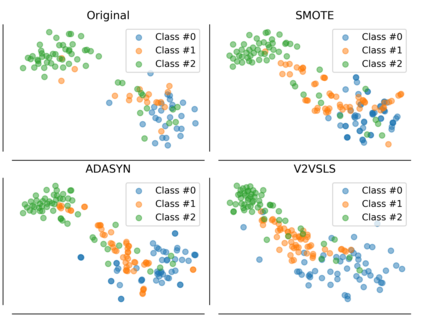
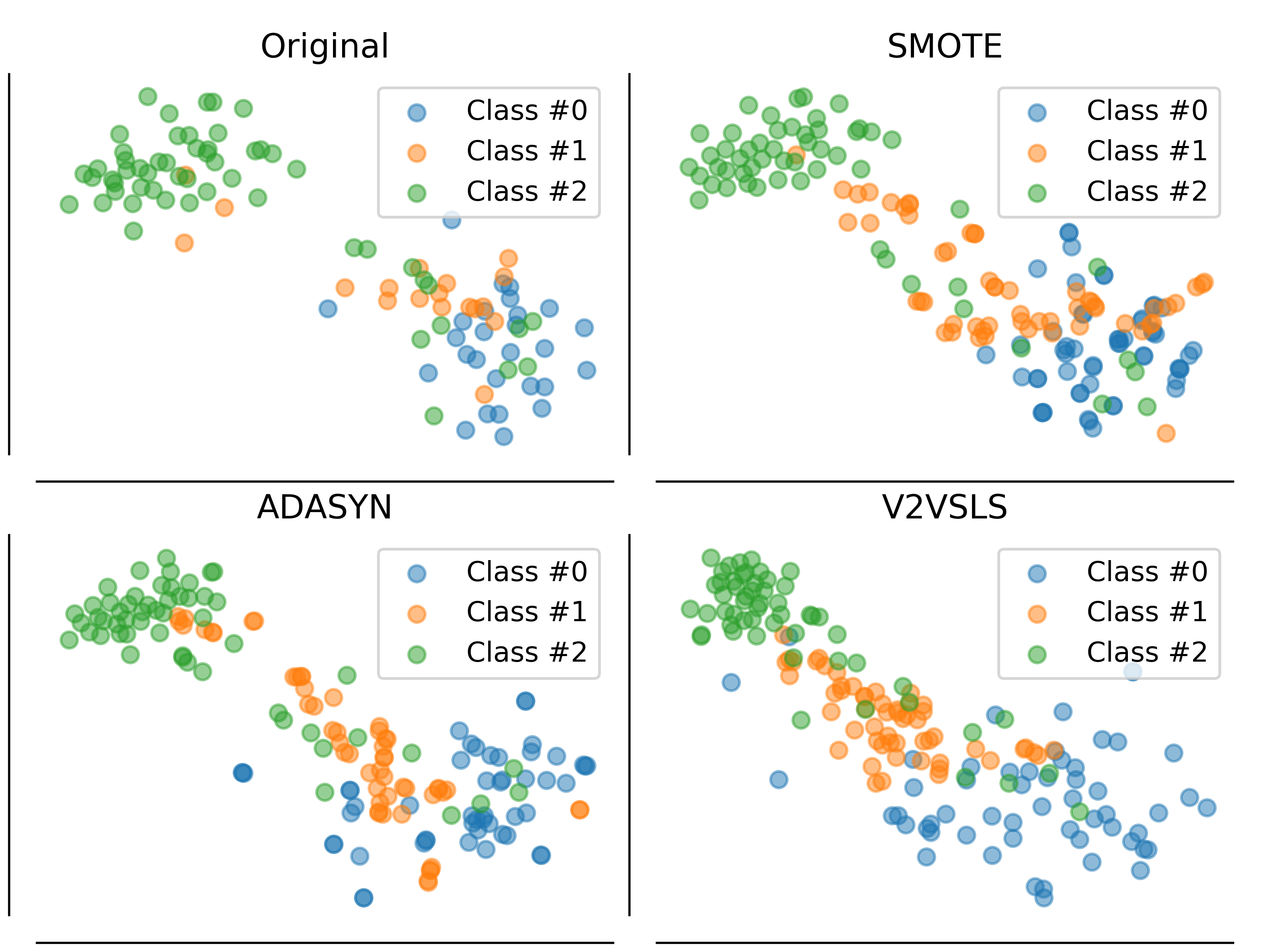
k-Nearest Neighbors is one of the most fundamental but effective classification models. In this paper, we propose two families of models built on a sequence to sequence model and a memory network model to mimic the k-Nearest Neighbors model, which generate a sequence of labels, a sequence of out-of-sample feature vectors and a final label for classification, and thus they could also function as oversamplers. We also propose 'out-of-core' versions of our models which assume that only a small portion of data can be loaded into memory. Computational experiments show that our models on structured datasets outperform k-Nearest Neighbors, a feed-forward neural network, XGBoost, lightGBM, random forest and a memory network, due to the fact that our models must produce additional output and not just the label. On image and text datasets, the performance of our model is close to many state-of-the-art deep models. As an oversampler on imbalanced datasets, the sequence to sequence kNN model often outperforms Synthetic Minority Over-sampling Technique and Adaptive Synthetic Sampling.
翻译:K- Nearest 邻里bors 是最为基本但有效的分类模型之一 。 在本文中, 我们提议了两个模型的组组, 建在序列序列序列模型上的模型和模拟 k- Nearest 邻里bors 模型的内存网络模型, 产生标签序列、 标本外特征矢量序列和最后分类标签, 因此它们也可以发挥超标功能 。 我们还提议了“ 核心外” 版本的模型, 这些模型假设只有一小部分数据可以装入记忆中。 计算实验显示, 我们关于结构化数据集的模型, 超越了 K- Nearest 邻里bors、 种子前向神经网络、 XGBoost、 灯GBM、 随机森林和记忆网络, 这是因为我们的模型必须产生额外输出, 而不仅仅是标签。 在图像和文本数据集上, 我们模型的性能接近许多最先进的深层模型。 作为失衡数据设置的过版模型, 以及系统Small- samplering the demodel- sy