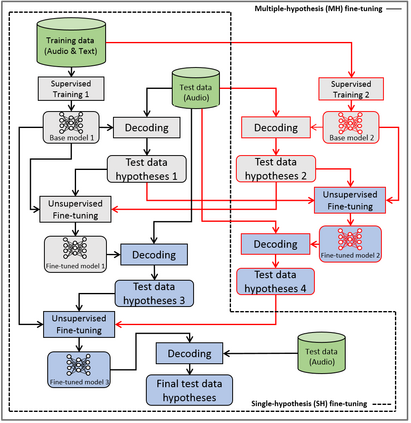
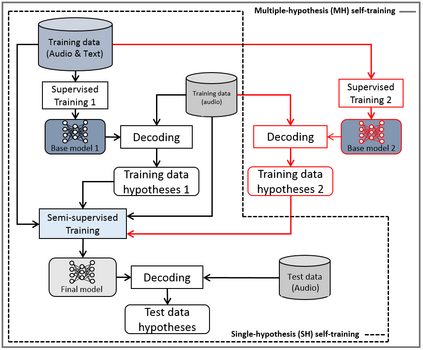
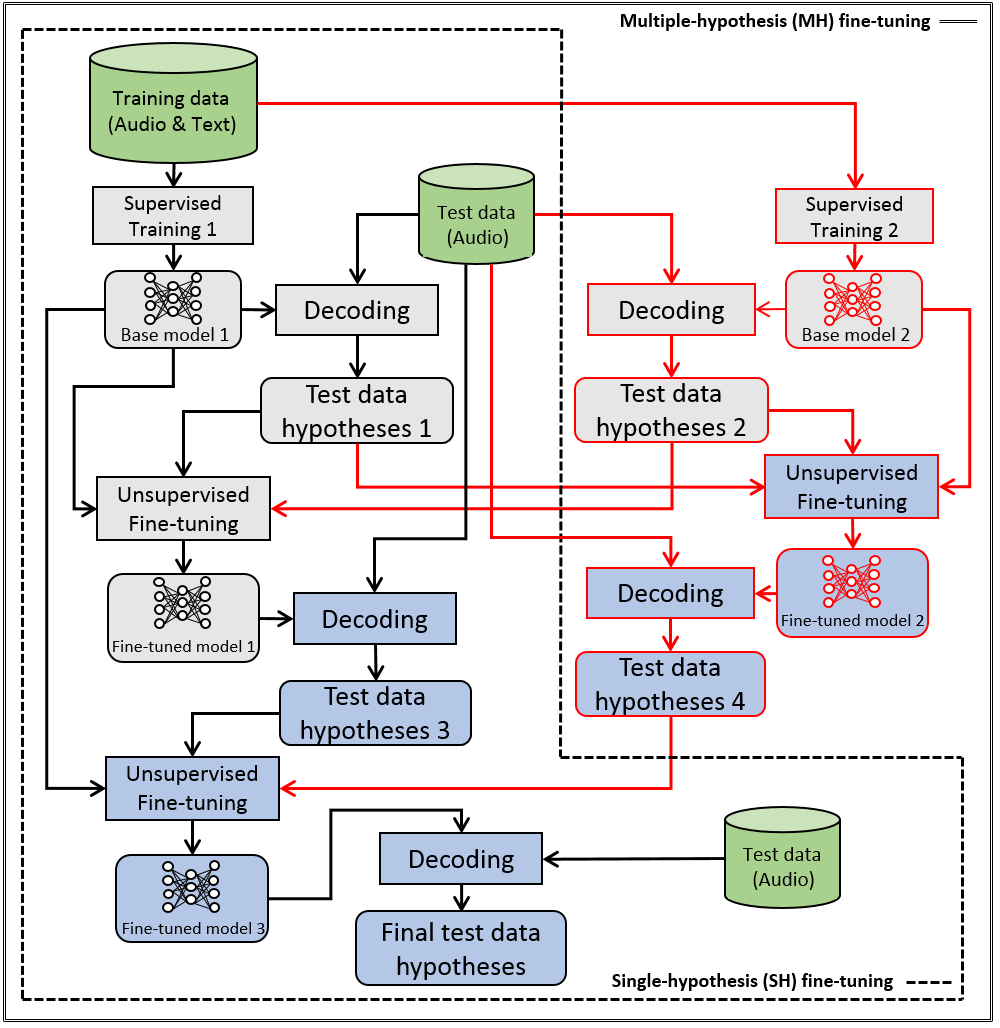
This paper proposes a new approach to perform unsupervised fine-tuning and self-training using unlabeled speech data for recurrent neural network (RNN)-Transducer (RNN-T) end-to-end (E2E) automatic speech recognition (ASR) systems. Conventional systems perform fine-tuning/self-training using ASR hypothesis as the targets when using unlabeled audio data and are susceptible to the ASR performance of the base model. Here in order to alleviate the influence of ASR errors while using unlabeled data, we propose a multiple-hypothesis RNN-T loss that incorporates multiple ASR 1-best hypotheses into the loss function. For the fine-tuning task, ASR experiments on Librispeech show that the multiple-hypothesis approach achieves a relative reduction of 14.2% word error rate (WER) when compared to the single-hypothesis approach, on the test_other set. For the self-training task, ASR models are trained using supervised data from Wall Street Journal (WSJ), Aurora-4 along with CHiME-4 real noisy data as unlabeled data. The multiple-hypothesis approach yields a relative reduction of 3.3% WER on the CHiME-4's single-channel real noisy evaluation set when compared with the single-hypothesis approach.
翻译:本文提出一种新的方法,即使用无标签音频网络自动语音识别系统进行不受监督的微调和自我培训,对经常神经网络(RNNN)-传感器(RNN-T)端到端自动语音识别系统进行无标签语音数据调整和自我培训。 常规系统使用无标签音频数据进行微调/自我培训,将ASR假设作为目标进行微调/自我培训,并容易受基准模型ASR性能表现的影响。 为了减轻ASR错误的影响,同时使用无标签数据,我们提出了一种多功能性能测试损失,将多个ASR1最佳假设纳入损失功能。关于Librispeech的ASR实验显示,在微调任务中,使用ASR假设作为目标,使用ASR的假设进行微调/自我培训,使用Wall Street Journal的监管数据(WSJ),与CHIME-4的最佳假设,同时使用CHIME-4, 将实际冷压数据作为单项单项磁盘,比对单项单项数据进行比较。