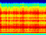
This paper presents a deep learning system applied for detecting anomalies from respiratory sound recordings. Initially, our system begins with audio feature extraction using Gammatone and Continuous Wavelet transformation. This step aims to transform the respiratory sound input into a two-dimensional spectrogram where both spectral and temporal features are presented. Then, our proposed system integrates Inception-residual-based backbone models combined with multi-head attention and multi-objective loss to classify respiratory anomalies. In this work, we conducted experiments over the benchmark dataset of SPRSound (The Open-Source SJTU Paediatric Respiratory Sound) proposed by the IEEE BioCAS 2022 challenge. As regards the Score computed by an average between the average score and harmonic score, our proposed system gained significant improvements of 9.7%, 15.8%, 17.0%, and 9.4% in Task 1-1, Task 1-2, Task 2-1, and Task 2-2 compared to the challenge baseline system. Notably, we achieved the Top-1 performance in Task 2-1 with the highest Score of 73.7%.
翻译:本文展示了用于检测呼吸系统录音记录异常现象的深层学习系统。 最初, 我们的系统从使用伽马通和持续波盘变换的音频特征提取开始。 这个步骤旨在将呼吸声输入转换成双维光谱, 显示光谱和时间特征。 然后, 我们提议的系统整合了基于感知- 留守的骨架模型, 加上多头注意力和多目标损失, 以对呼吸系统异常进行分类。 在这项工作中, 我们实验了IEEE BioCAS 2022 挑战提议的SPRSound(开放源SJTU儿科呼吸系统声音)基准数据集。 关于平均分数和口音分之间的平均计分,我们提议的系统在任务1-1、 任务1-2、任务2-1和任务2-2中取得了9.4%的重大改进。 值得注意的是, 我们在任务2-1中实现了第1项中的顶级业绩, 最高分为73.7 %。</s>