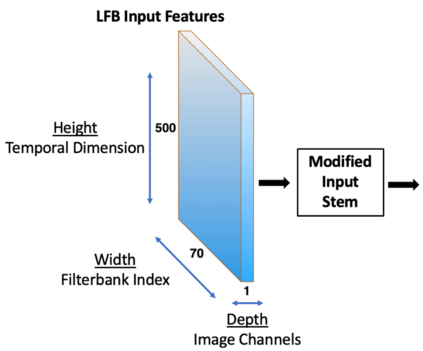
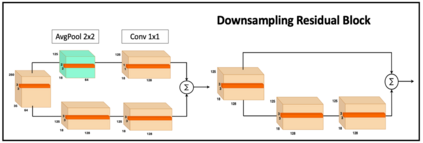
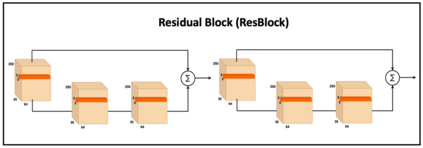
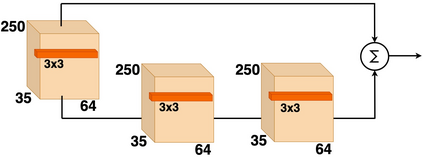
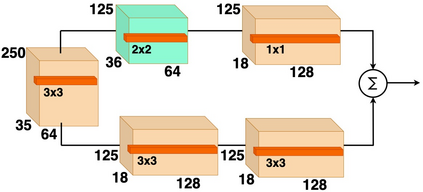
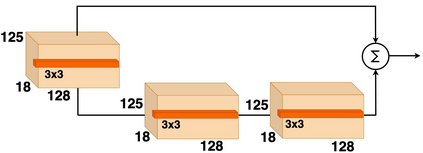
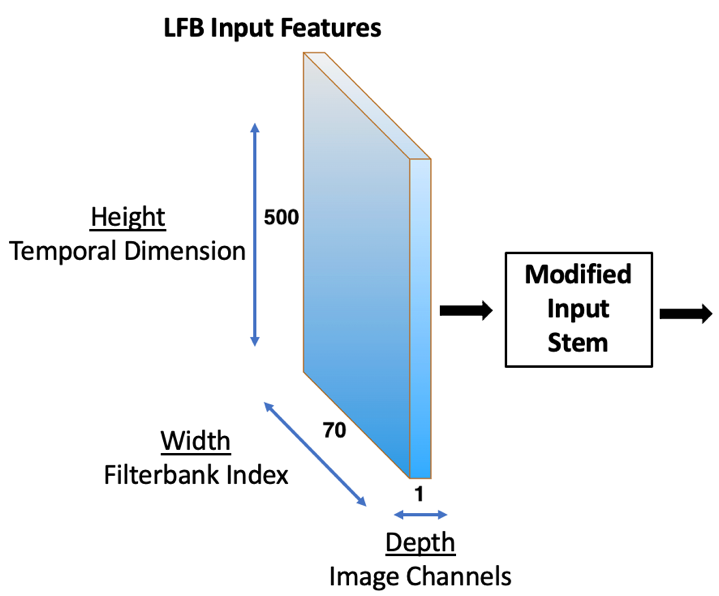
Recent advances in artificial speech and audio technologies have improved the abilities of deep-fake operators to falsify media and spread malicious misinformation. Anyone with limited coding skills can use freely available speech synthesis tools to create convincing simulations of influential speakers' voices with the malicious intent to distort the original message. With the latest technology, malicious operators do not have to generate an entire audio clip; instead, they can insert a partial manipulation or a segment of synthetic speech into a genuine audio recording to change the entire context and meaning of the original message. Detecting these insertions is especially challenging because partially manipulated audio can more easily avoid synthetic speech detectors than entirely fake messages can. This paper describes a potential partial synthetic speech detection system based on the x-ResNet architecture with a probabilistic linear discriminant analysis (PLDA) backend and interleaved aware score processing. Experimental results suggest that the PLDA backend results in a 25% average error reduction among partially synthesized datasets over a non-PLDA baseline.
翻译:人工言语和音频技术的最新进步提高了深假操作员伪造媒体和传播恶意错误信息的能力。任何掌握有限编码技能的人都可以使用自由可用的语音合成工具,对有影响力的演讲者的声音进行令人信服的模拟,其恶意意图是扭曲原始信息。使用最新技术,恶意操作员不必生成完整的音频剪辑;相反,他们可以在真实的录音中插入部分操纵或合成言词的一部分,以改变原始信息的整个背景和含义。检测这些插入尤其具有挑战性,因为部分操作的音频比完全假信息更容易避免合成语音探测器。本文描述了基于x-ResNet结构的潜在部分合成语音探测系统,其基础是概率直线式声分析后端和内部认知分数处理。实验结果表明,PLDA后端在非PLDA基线上部分合成数据集之间平均减少25%的错误。