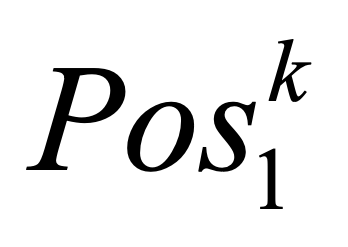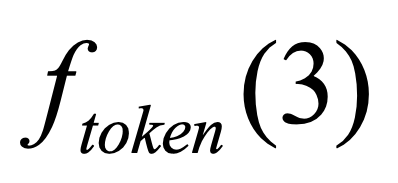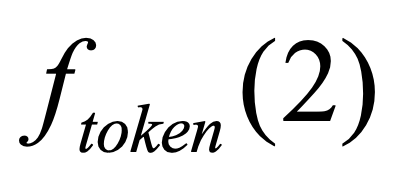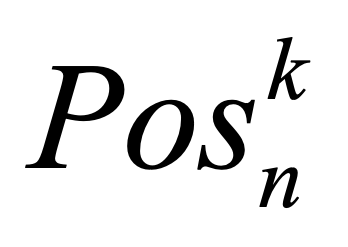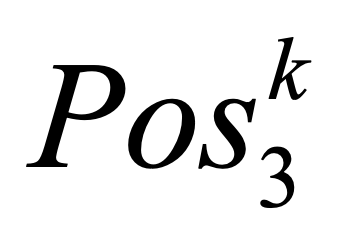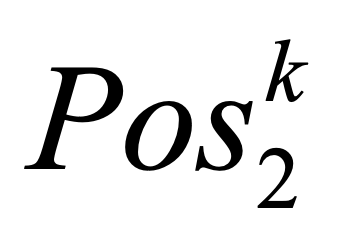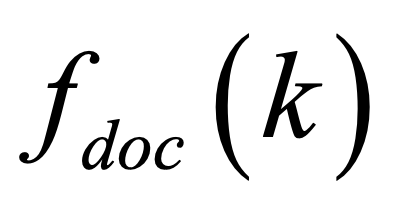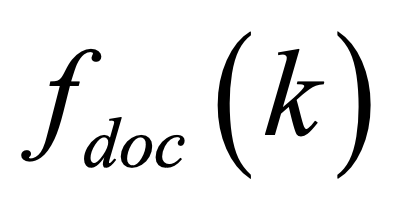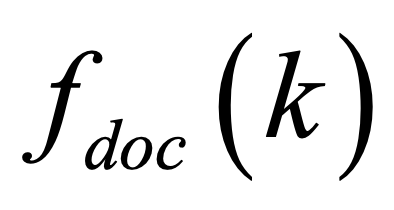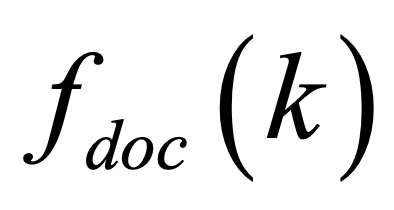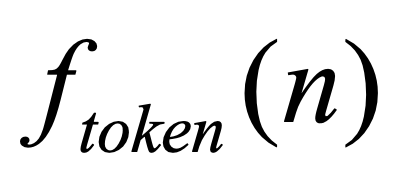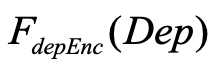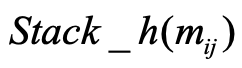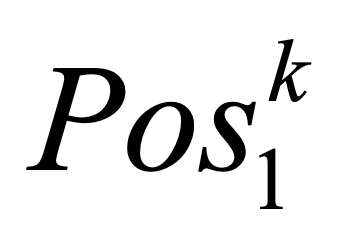One key challenge in multi-document summarization is to capture the relations among input documents that distinguish between single document summarization (SDS) and multi-document summarization (MDS). Few existing MDS works address this issue. One effective way is to encode document positional information to assist models in capturing cross-document relations. However, existing MDS models, such as Transformer-based models, only consider token-level positional information. Moreover, these models fail to capture sentences' linguistic structure, which inevitably causes confusions in the generated summaries. Therefore, in this paper, we propose document-aware positional encoding and linguistic-guided encoding that can be fused with Transformer architecture for MDS. For document-aware positional encoding, we introduce a general protocol to guide the selection of document encoding functions. For linguistic-guided encoding, we propose to embed syntactic dependency relations into the dependency relation mask with a simple but effective non-linear encoding learner for feature learning. Extensive experiments show the proposed model can generate summaries with high quality.
翻译:在多文件总和中,一个关键挑战是捕捉那些区分单一文件总和(SDS)和多文件总和(MDS)的输入文件之间的关系。现有的MDS很少能解决这个问题。一种有效的方法是将文件位置信息编码成编码,以协助模型捕捉交叉文件关系。但是,现有的MDS模型,例如以变换器为基础的模型,只考虑象征性的定位信息。此外,这些模型未能捕捉到判决的语言结构,这不可避免地在生成的摘要中造成混乱。因此,我们在本文件中提议,文件敏化位置编码和语言指导编码可以与MDS的变换器结构结合。对于文件总协议,我们引入了用于指导文件编码功能选择的一般协议。对于语言编码,我们建议将合成依赖关系与一个简单而有效的非线性编码学习器连接成特征学习。广泛的实验显示,拟议的模型可以产生高质量的摘要。