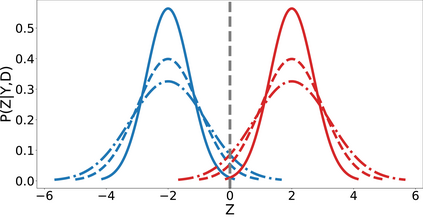
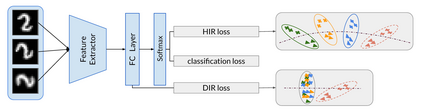
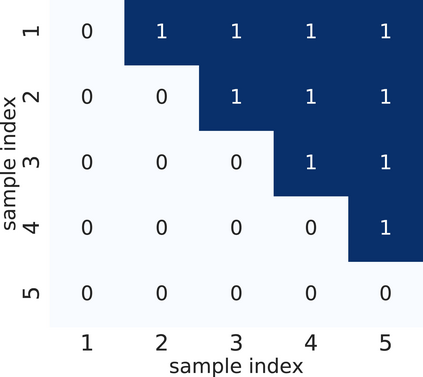
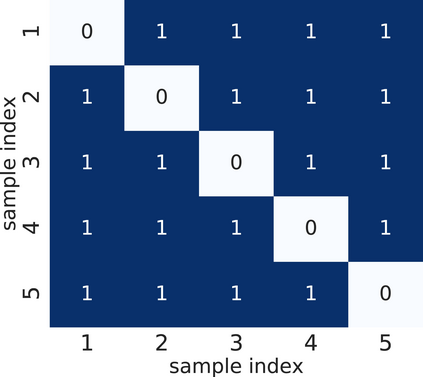
In domain generalization, multiple labeled non-independent and non-identically distributed source domains are available during training while neither the data nor the labels of target domains are. Currently, learning so-called domain invariant representations (DIRs) is the prevalent approach to domain generalization. In this work, we define DIRs employed by existing works in probabilistic terms and show that by learning DIRs, overly strict requirements are imposed concerning the invariance. Particularly, DIRs aim to perfectly align representations of different domains, i.e. their input distributions. This is, however, not necessary for good generalization to a target domain and may even dispose of valuable classification information. We propose to learn so-called hypothesis invariant representations (HIRs), which relax the invariance assumptions by merely aligning posteriors, instead of aligning representations. We report experimental results on public domain generalization datasets to show that learning HIRs is more effective than learning DIRs. In fact, our approach can even compete with approaches using prior knowledge about domains.
翻译:在一般化方面,在培训期间,可找到多个有标签的不独立和不识别分布源域,而目标域的数据和标签则不存在。目前,学习所谓的域差异表示(DIRs)是通用的通用方法。在这项工作中,我们以概率化术语界定现有作品采用的DIRs,并表明通过学习DIRs,对差异性要求过于严格。特别是,DIRs旨在完美地统一不同域(即其输入分布)的表述。然而,这对向目标域提供良好概括并甚至可能处置有价值的分类信息来说,是没有必要的。我们提议学习所谓的域差异表示(HIRs)假设(HIRs),这些假设通过仅仅调整后方,而不是调整表达方式来放松差异假设。我们报告公共域通用数据集的实验结果,以表明学习HIRs比学习DIRs更有效。事实上,我们的方法甚至可以与使用以往领域知识的方法竞争。