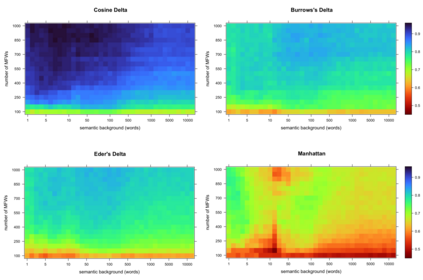
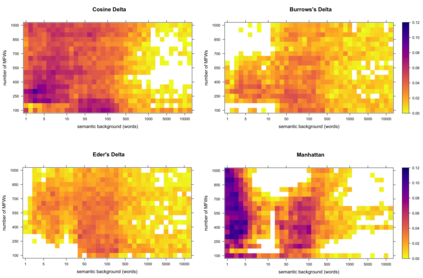
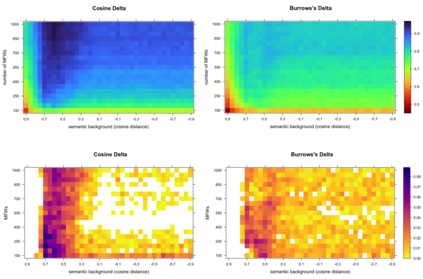
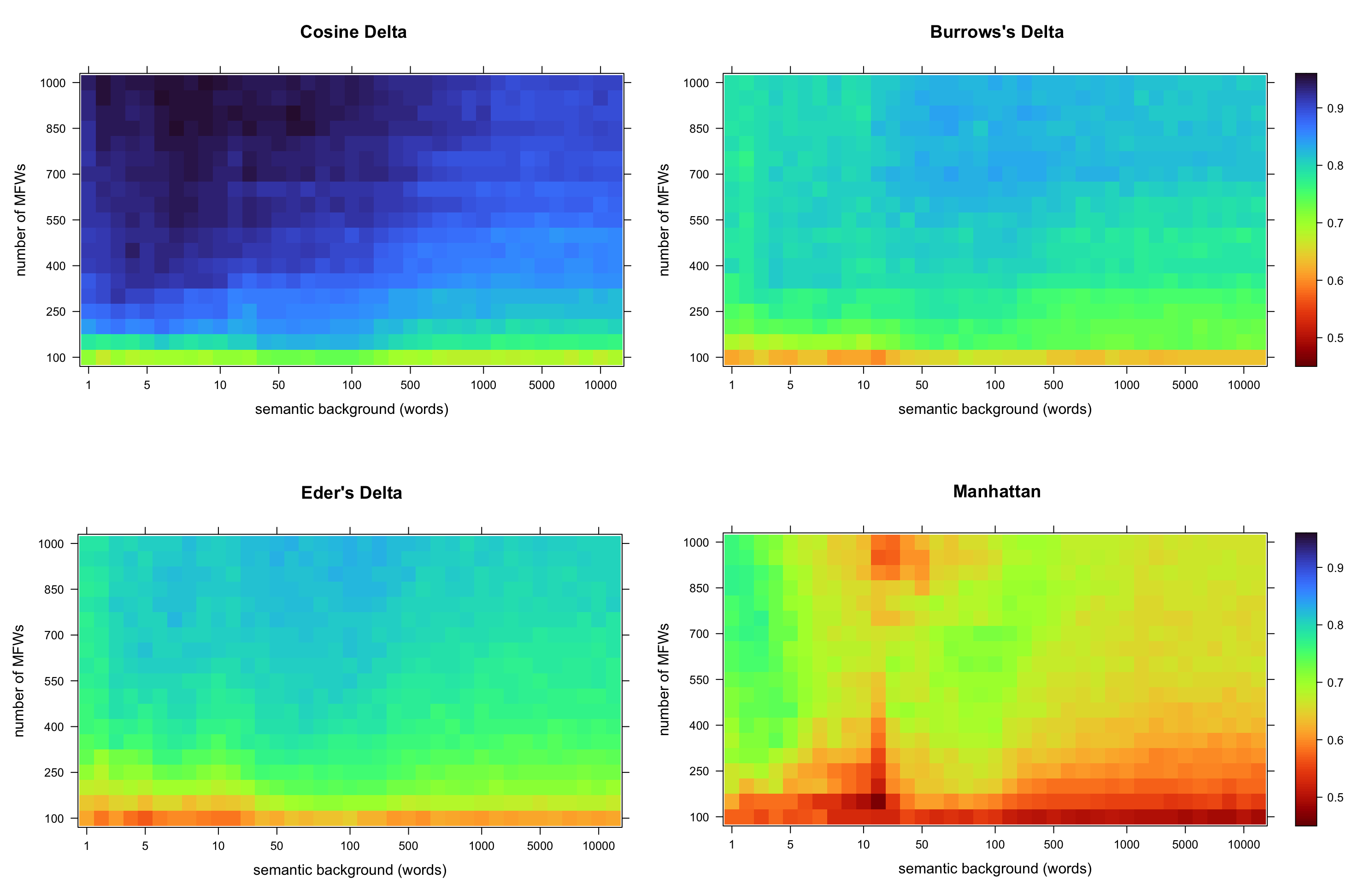
In this paper, I introduce a simple method of computing relative word frequencies for authorship attribution and similar stylometric tasks. Rather than computing relative frequencies as the number of occurrences of a given word divided by the total number of tokens in a text, I argue that a more efficient normalization factor is the total number of relevant tokens only. The notion of relevant words includes synonyms and, usually, a few dozen other words in some ways semantically similar to a word in question. To determine such a semantic background, one of word embedding models can be used. The proposed method outperforms classical most-frequent-word approaches substantially, usually by a few percentage points depending on the input settings.
翻译:在本文中,我引入了一种简单的计算作者归属和类似音量测量任务的相对词频率的方法。与其计算相对频率,因为某个单词的发生次数除以文本中标记的总数,我争论说,一个更有效率的正常化因素是只有相关符号的总数。相关词的概念包括同义词,通常还有几十个其他词,在某些方面,与相关词的语义相似。为了确定这样的语义背景,可以使用一个词嵌入模型。拟议方法大大优于经典最经常的词法,通常根据输入设置以几个百分点表示。