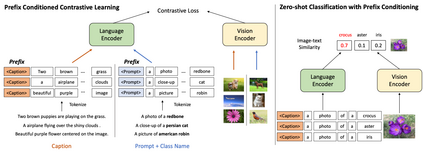
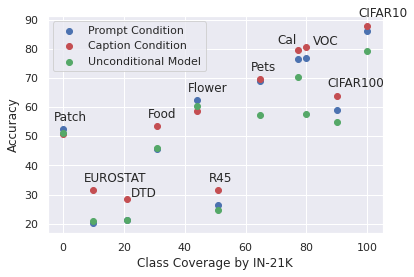
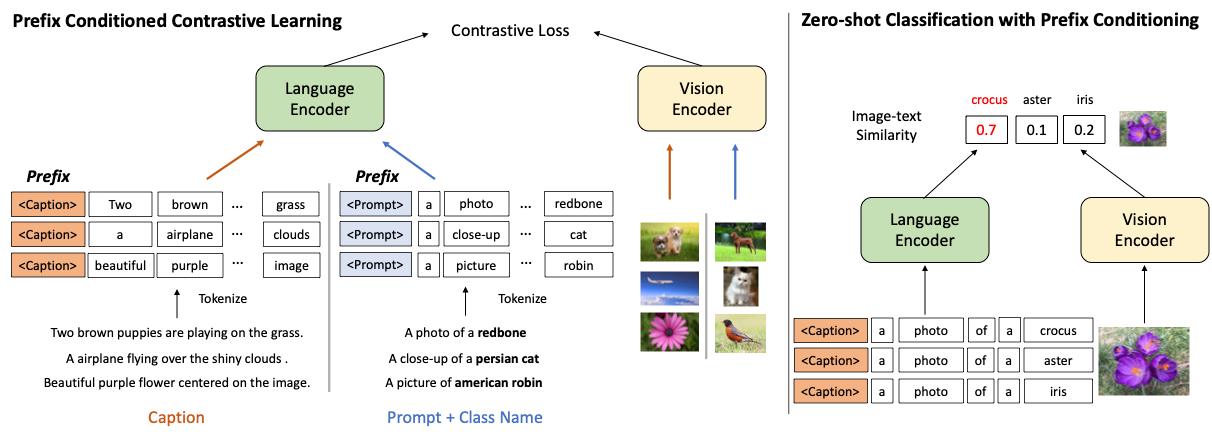
Vision-language contrastive learning suggests a new learning paradigm by leveraging a large amount of image-caption-pair data. The caption supervision excels at providing wide coverage in vocabulary that enables strong zero-shot image recognition performance. On the other hand, label supervision offers to learn more targeted visual representations that are label-oriented and can cover rare categories. To gain the complementary advantages of both kinds of supervision for contrastive image-caption pre-training, recent works have proposed to convert class labels into a sentence with pre-defined templates called prompts. However, a naive unification of the real caption and the prompt sentences could lead to a complication in learning, as the distribution shift in text may not be handled properly in the language encoder. In this work, we propose a simple yet effective approach to unify these two types of supervision using prefix tokens that inform a language encoder of the type of the input sentence (e.g., caption or prompt) at training time. Our method is generic and can be easily integrated into existing VL pre-training objectives such as CLIP or UniCL. In experiments, we show that this simple technique dramatically improves the performance in zero-shot image recognition accuracy of the pre-trained model.
翻译:对比语言的对比式学习建议了一种新的学习模式,即利用大量图像描述数据。标题监管优于在词汇中提供广泛的覆盖面,从而能够产生强烈的零光图像识别性能。另一方面,标签监管可以学习更有针对性的、以标签为导向且可以涵盖稀有类别的视觉表现。为了获得两种类型监督的互补优势,用于对比图像描述培训前的图像描述,最近的工作建议将类标签转换为带有预定义模板的句子,称为提示。然而,对真实标题和快速句子的天真统一可能导致学习复杂化,因为文本的分布变化可能无法在语言编码器中正确处理。在这项工作中,我们提出了一个简单而有效的方法,用前缀符号将这两种类型的监督统一起来,在培训时间将输入句(如字幕或提示)的语义编码转换成语言编码。我们的方法是通用的,可以很容易地融入现有的VLI前培训目标,如CLIP或UICL。在实验中,我们展示了这种简单技术在零点图像识别前的精确性能大大改进。