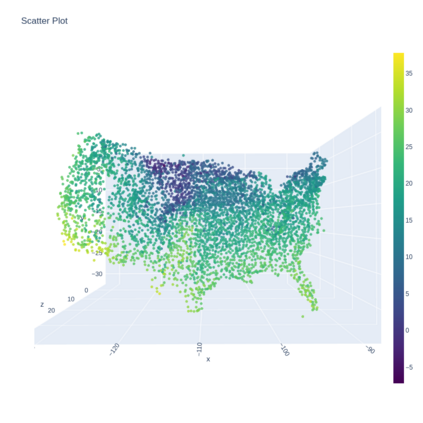
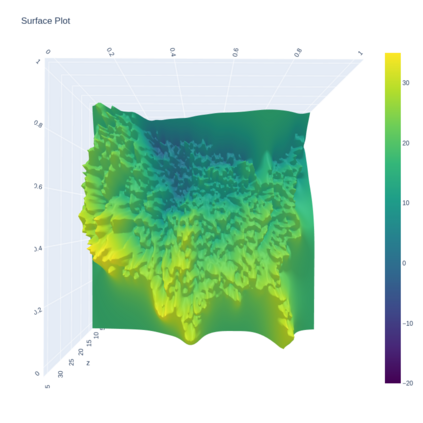
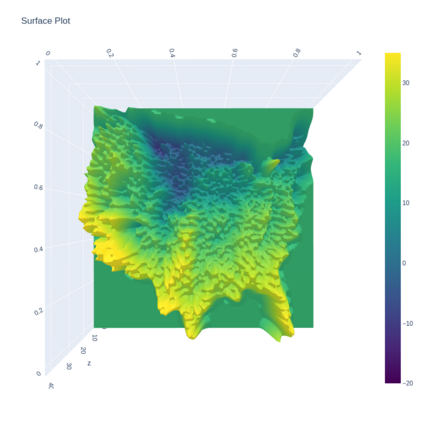
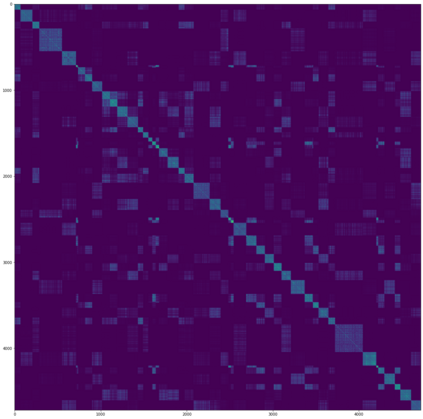
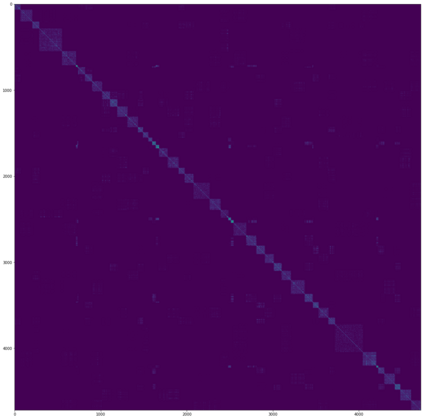
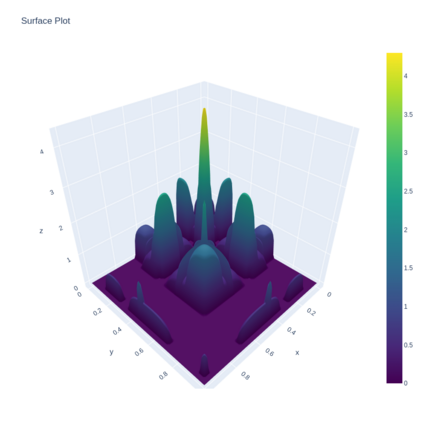
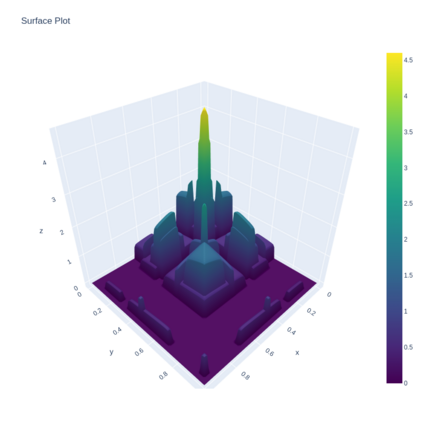
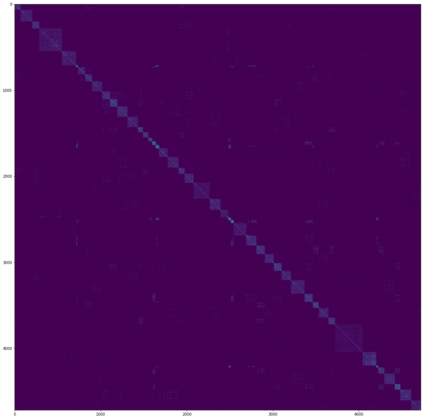
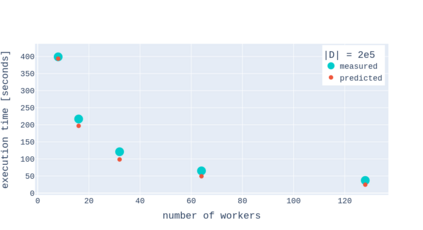
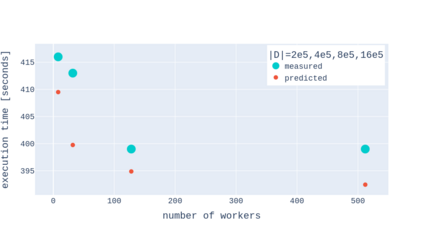
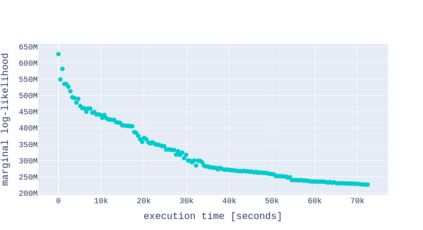
A Gaussian Process (GP) is a prominent mathematical framework for stochastic function approximation in science and engineering applications. This success is largely attributed to the GP's analytical tractability, robustness, non-parametric structure, and natural inclusion of uncertainty quantification. Unfortunately, the use of exact GPs is prohibitively expensive for large datasets due to their unfavorable numerical complexity of $O(N^3)$ in computation and $O(N^2)$ in storage. All existing methods addressing this issue utilize some form of approximation -- usually considering subsets of the full dataset or finding representative pseudo-points that render the covariance matrix well-structured and sparse. These approximate methods can lead to inaccuracies in function approximations and often limit the user's flexibility in designing expressive kernels. Instead of inducing sparsity via data-point geometry and structure, we propose to take advantage of naturally-occurring sparsity by allowing the kernel to discover -- instead of induce -- sparse structure. The premise of this paper is that GPs, in their most native form, are often naturally sparse, but commonly-used kernels do not allow us to exploit this sparsity. The core concept of exact, and at the same time sparse GPs relies on kernel definitions that provide enough flexibility to learn and encode not only non-zero but also zero covariances. This principle of ultra-flexible, compactly-supported, and non-stationary kernels, combined with HPC and constrained optimization, lets us scale exact GPs well beyond 5 million data points.
翻译:高斯进程(GP)是科学和工程应用中精密功能近似的一个突出的数学框架。 这一成功在很大程度上归功于GP的分析可移植性、稳健性、非参数结构以及自然纳入不确定性量化。 不幸的是,精确的GP对于大型数据集来说成本极高,因为其计算和储存中的数字复杂性都令人难以接受,其数字复杂性分别为O(N)3美元和O(N)2美元。所有解决这一问题的现有方法都使用某种近似形式 -- -- 通常考虑到完整的数据集的子集或找到代表的假点,使共变矩阵结构结构良好和稀少。这些近似方法可能导致功能近似不准确,并常常限制用户设计表态内核内核的灵活性。我们建议利用自然产生的紧张性,让我们内核发现 -- -- 而不是诱导 -- -- 压缩结构。 本文的前提是,GPGP不是在最本地的变异性矩阵中,而是自然地、普通地、普通地、核心地、核心地、核心地、核心地、核心地、内部的变现。