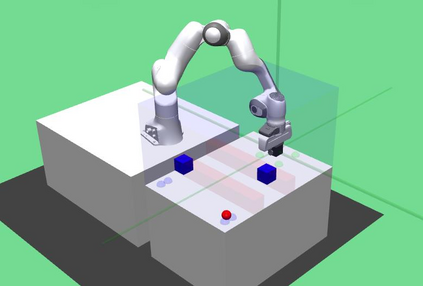
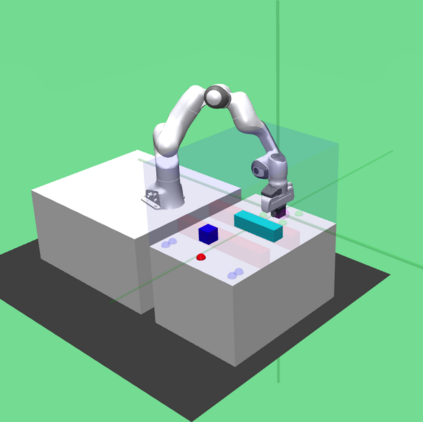
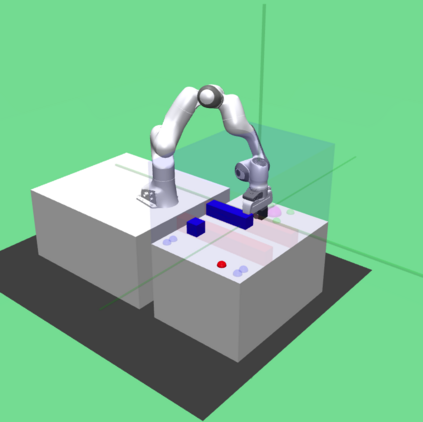
Deep reinforcement learning (RL) has been endowed with high expectations in tackling challenging manipulation tasks in an autonomous and self-directed fashion. Despite the significant strides made in the development of reinforcement learning, the practical deployment of this paradigm is hindered by at least two barriers, namely, the engineering of a reward function and ensuring the safety guaranty of learning-based controllers. In this paper, we address these challenging limitations by proposing a framework that merges a reinforcement learning \lstinline[columns=fixed]{planner} that is trained using sparse rewards with a model predictive controller (MPC) \lstinline[columns=fixed]{actor}, thereby offering a safe policy. On the one hand, the RL \lstinline[columns=fixed]{planner} learns from sparse rewards by selecting intermediate goals that are easy to achieve in the short term and promising to lead to target goals in the long term. On the other hand, the MPC \lstinline[columns=fixed]{actor} takes the suggested intermediate goals from the RL \lstinline[columns=fixed]{planner} as the input and predicts how the robot's action will enable it to reach that goal while avoiding any obstacles over a short period of time. We evaluated our method on four challenging manipulation tasks with dynamic obstacles and the results demonstrate that, by leveraging the complementary strengths of these two components, the agent can solve manipulation tasks in complex, dynamic environments safely with a $100\%$ success rate. Videos are available at \url{https://videoviewsite.wixsite.com/mpc-hgg}.
翻译:深度强化学习已经被寄予厚望,可以在自主和自我导向的方式下处理具有挑战性的操作任务。尽管在强化学习的发展方面取得了重大进展,但这种范例的实际部署受到至少两个障碍的限制,即,其奖励函数的设计以及学习基于控制器的安全保证。本文通过提议一个框架,融合了一个使用稀疏奖励训练的强化学习规划器和一个模型预测控制器(MPC)执行器,从而提供了安全策略,来解决这些限制性条件。On the one hand,强化学习规划器通过选择在短期内容易完成且有望在长期内导致目标目标的中间目标,从稀疏奖励中进行学习。On the other hand,MPC执行器从强化学习规划器中的推荐中间目标作为输入,并预测机器人的动作将如何使其在短期内达到该目标,同时避免任何障碍。我们在四个具有动态障碍的挑战性操作任务上评估了我们的方法,结果表明,通过利用这两个组件的互补优势,代理可以在复杂且动态的环境中安全地解决操作任务,并实现 100%的成功率。视频可在此处查看 \url{https://videoviewsite.wixsite.com/mpc-hgg}.