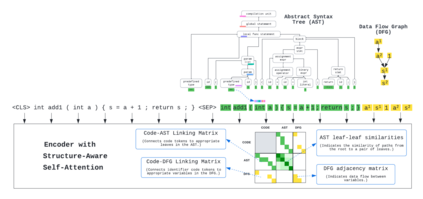
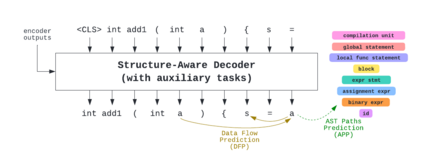
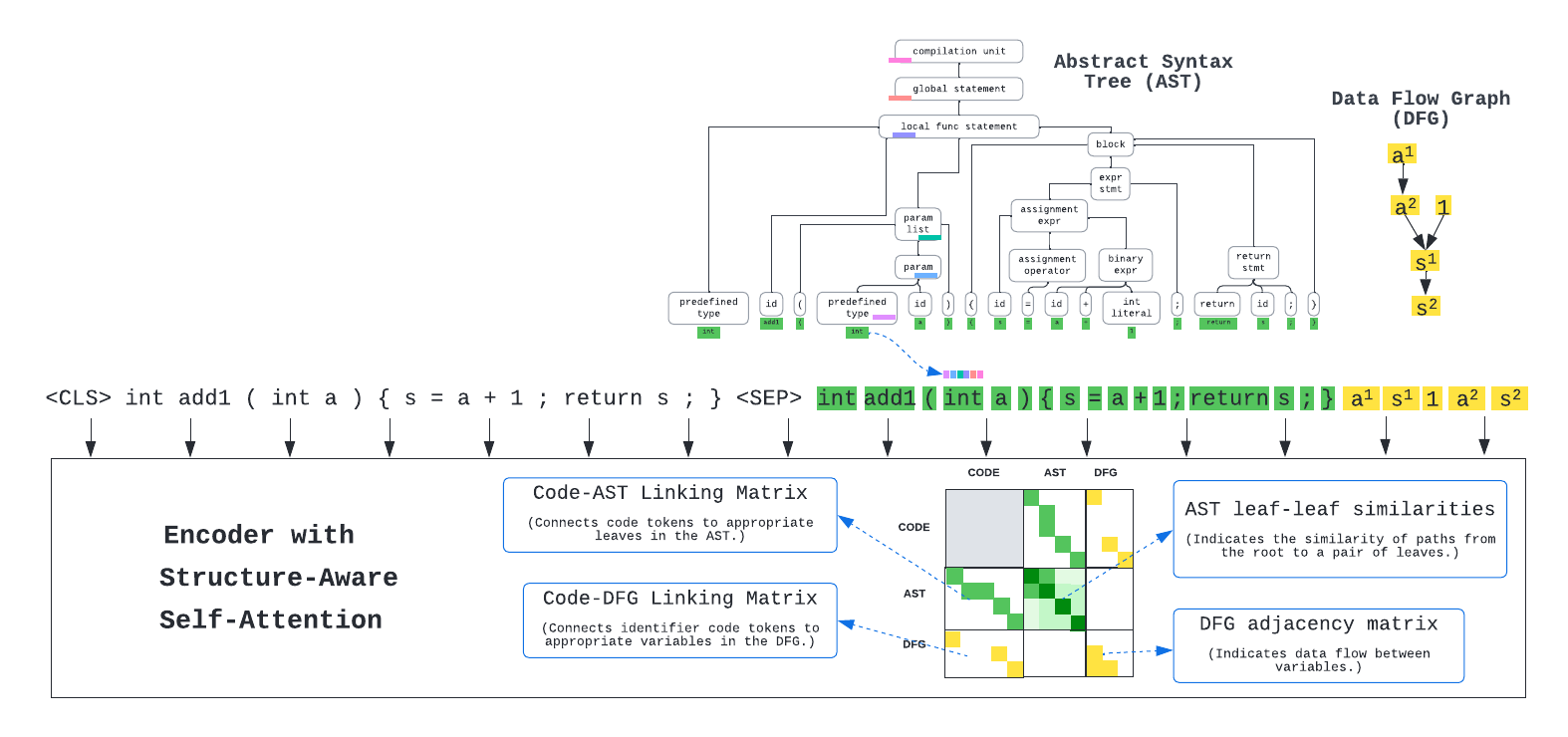
There has been a recent surge of interest in automating software engineering tasks using deep learning. This work addresses the problem of code generation where the goal is to generate target code given source code in a different language or a natural language description. Most of the state-of-the-art deep learning models for code generation use training strategies that are primarily designed for natural language. However, understanding and generating code requires a more rigorous comprehension of the code syntax and semantics. With this motivation, we develop an encoder-decoder Transformer model where both the encoder and decoder are trained to recognize the syntax and data flow in the source and target codes, respectively. We not only make the encoder structure-aware by leveraging the source code's syntax tree and data flow graph, but we also ensure that our decoder preserves the syntax and data flow of the target code by introducing two auxiliary tasks: AST (Abstract Syntax Tree) paths prediction and data flow prediction. To the best of our knowledge, this is the first work to introduce a structure-aware Transformer decoder to enhance the quality of generated code by modeling target syntax and data flow. The proposed StructCoder model achieves state-of-the-art performance on code translation and text-to-code generation tasks in the CodeXGLUE benchmark.
翻译:最近对利用深层学习实现软件工程任务自动化的兴趣激增。 这项工作解决了代码生成问题, 目标是以不同语言或自然语言描述生成目标代码源代码。 用于代码生成的大多数最先进的深层次学习模式都使用主要为自然语言设计的训练战略。 但是, 理解和生成代码需要更严格地理解代码语法和语义。 有了这一动机, 我们开发了一个编码- 解码变异器模型, 使编码和解码器分别接受培训, 以识别源代码和目标代码中的语法和数据流。 我们不仅通过利用源代码的语法树和数据流图来使编码结构认知, 我们还通过引入两个辅助任务, 即 AST (缩略语法树) 路径预测和数据流预测。 对我们的知识而言, 这是在源代码和目标代码中引入结构- 系统变异器解码解码的首项工作, 将生成的代码化为模型和数据流化, 实现生成的代码质量。