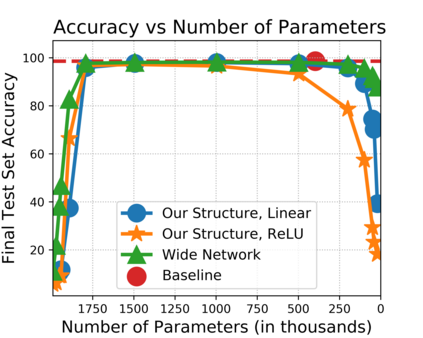
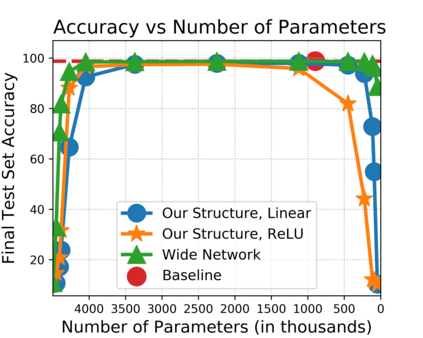
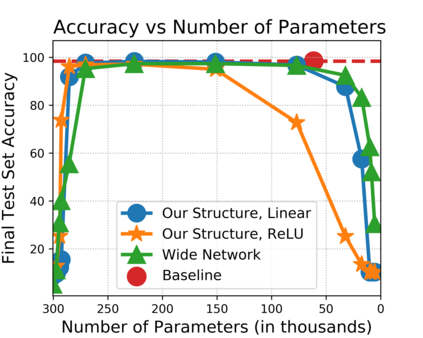
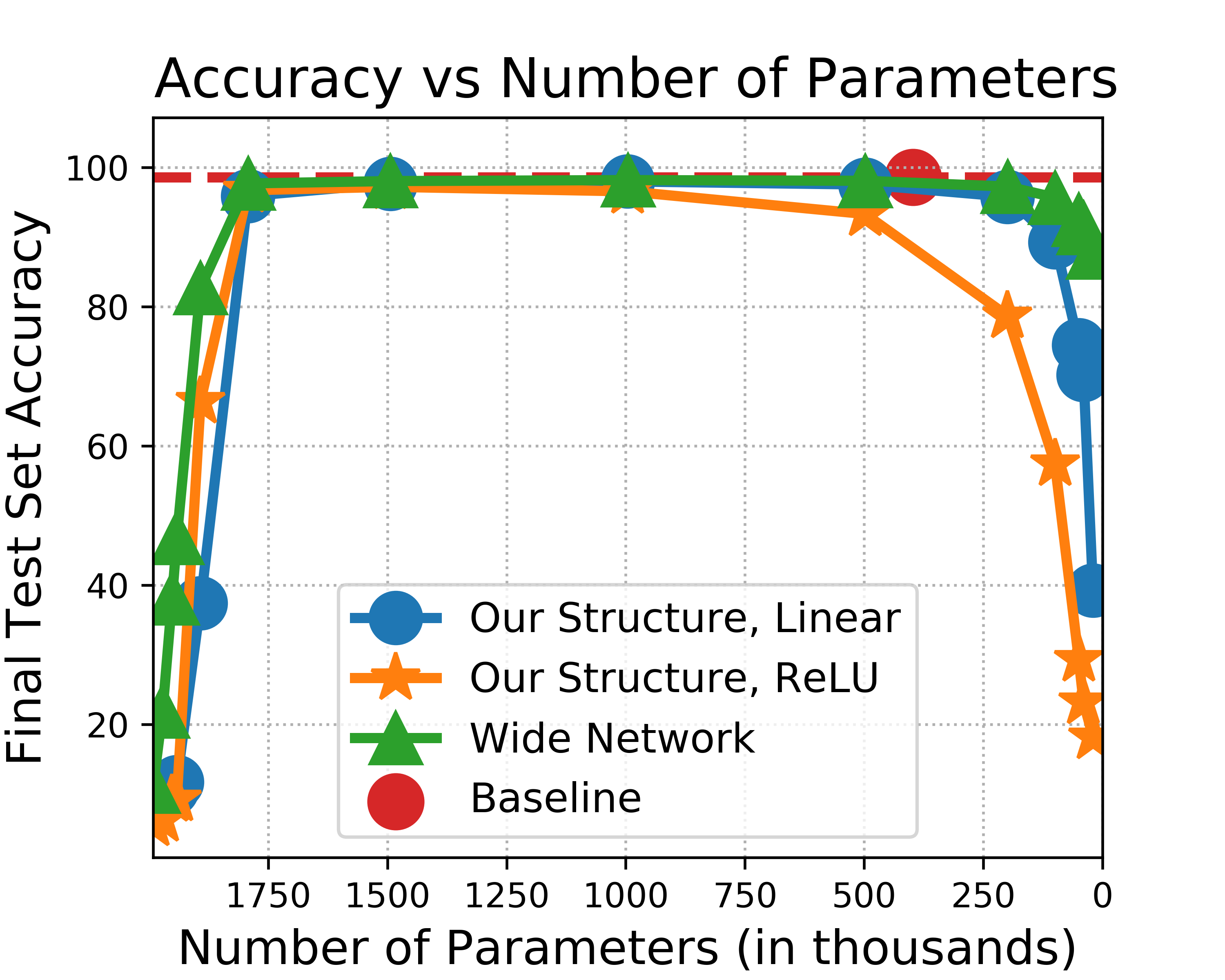
The strong {\it lottery ticket hypothesis} (LTH) postulates that one can approximate any target neural network by only pruning the weights of a sufficiently over-parameterized random network. A recent work by Malach et al. \cite{MalachEtAl20} establishes the first theoretical analysis for the strong LTH: one can provably approximate a neural network of width $d$ and depth $l$, by pruning a random one that is a factor $O(d^4l^2)$ wider and twice as deep. This polynomial over-parameterization requirement is at odds with recent experimental research that achieves good approximation with networks that are a small factor wider than the target. In this work, we close the gap and offer an exponential improvement to the over-parameterization requirement for the existence of lottery tickets. We show that any target network of width $d$ and depth $l$ can be approximated by pruning a random network that is a factor $O(\log(dl))$ wider and twice as deep. Our analysis heavily relies on connecting pruning random ReLU networks to random instances of the \textsc{SubsetSum} problem. We then show that this logarithmic over-parameterization is essentially optimal for constant depth networks. Finally, we verify several of our theoretical insights with experiments.
翻译:强力的彩票彩票假设 (LTH) 假设一个人只能通过剪切足够多参数随机网络的重量来近近任何目标神经网络。 Malach 等人(\ cite{ MalachEtAl20}) 最近的一项工作为强力LTH建立了第一个理论分析: 人们可以大致地接近一个宽度为美元和深度为美元和深度的神经网络, 随机网络可以比喻出一个宽度和深度为2倍的系数O( d ⁇ 4l2) 。 这个多数值超度要求与最近的实验性研究不相匹配, 而这些实验性研究与比目标大得多的网络实现良好近似。 在这项工作中, 我们缩小差距, 并为存在彩票的超度要求提供指数性改进。 我们显示, 任何宽度和深度为美元和深度为美元的目标网络的随机网络都可以比对随机网络进行比对一个系数( $\log( dl) ) 宽度和两倍的随机网络。 我们的分析主要依靠将精确的深度网络连接到这个随机的精确度 。