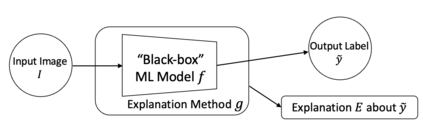
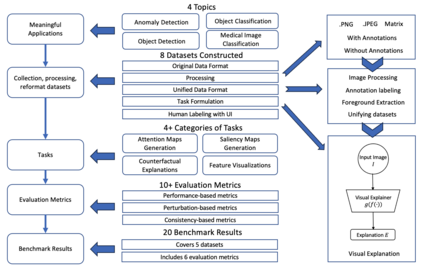
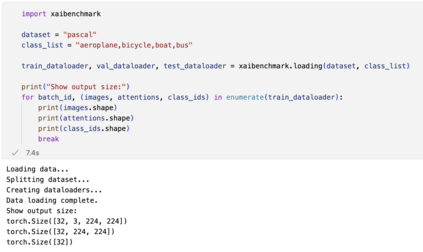
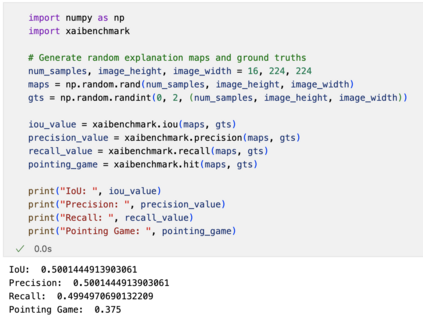
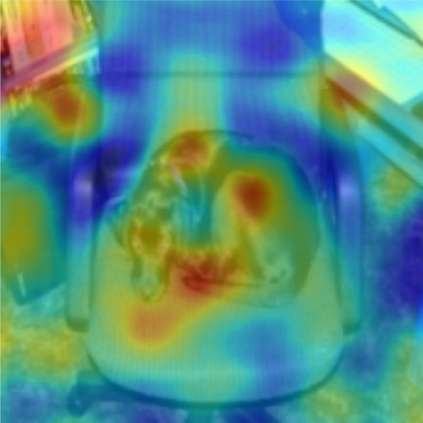
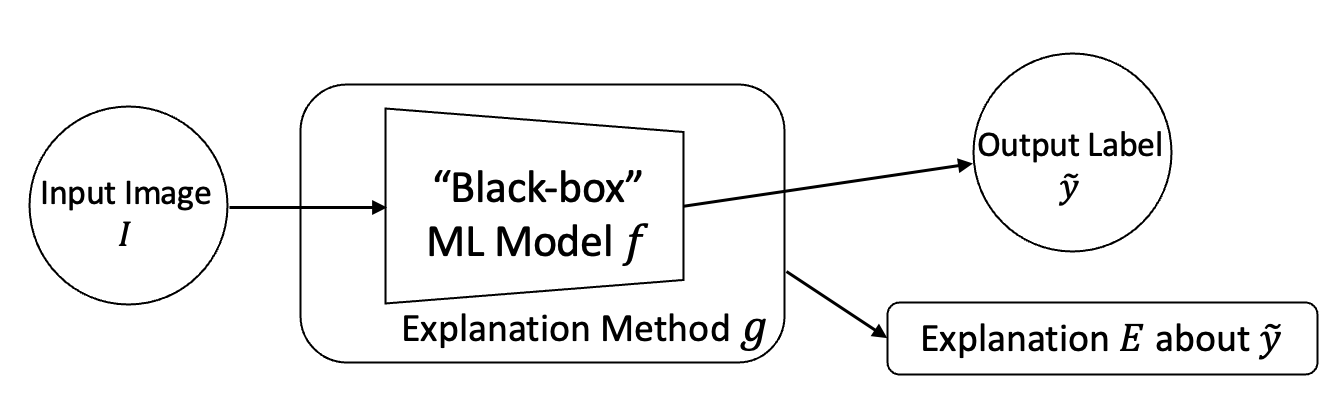
The rise of deep learning algorithms has led to significant advancements in computer vision tasks, but their "black box" nature has raised concerns regarding interpretability. Explainable AI (XAI) has emerged as a critical area of research aiming to open this "black box", and shed light on the decision-making process of AI models. Visual explanations, as a subset of Explainable Artificial Intelligence (XAI), provide intuitive insights into the decision-making processes of AI models handling visual data by highlighting influential areas in an input image. Despite extensive research conducted on visual explanations, most evaluations are model-centered since the availability of corresponding real-world datasets with ground truth explanations is scarce in the context of image data. To bridge this gap, we introduce an XAI Benchmark comprising a dataset collection from diverse topics that provide both class labels and corresponding explanation annotations for images. We have processed data from diverse domains to align with our unified visual explanation framework. We introduce a comprehensive Visual Explanation pipeline, which integrates data loading, preprocessing, experimental setup, and model evaluation processes. This structure enables researchers to conduct fair comparisons of various visual explanation techniques. In addition, we provide a comprehensive review of over 10 evaluation methods for visual explanation to assist researchers in effectively utilizing our dataset collection. To further assess the performance of existing visual explanation methods, we conduct experiments on selected datasets using various model-centered and ground truth-centered evaluation metrics. We envision this benchmark could facilitate the advancement of visual explanation models. The XAI dataset collection and easy-to-use code for evaluation are publicly accessible at https://xaidataset.github.io.
翻译:暂无翻译