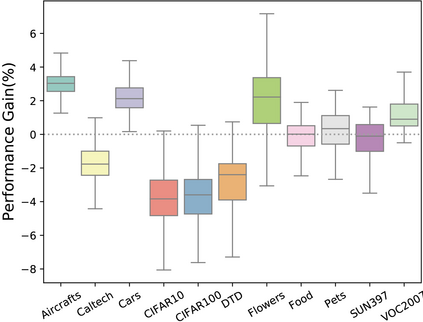
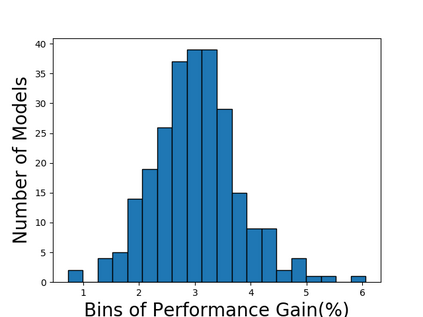
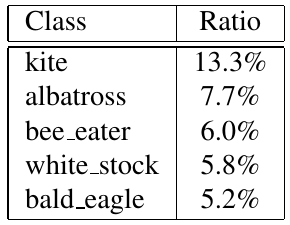
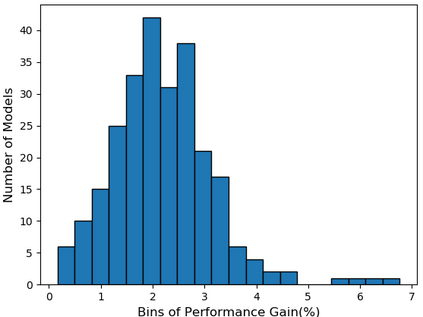
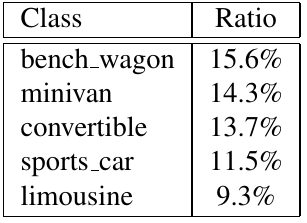
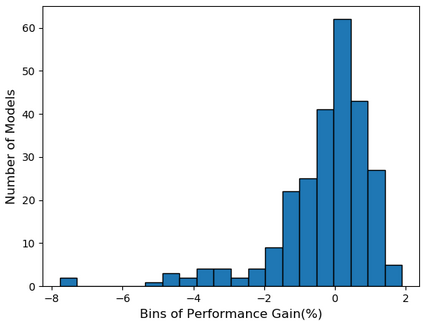
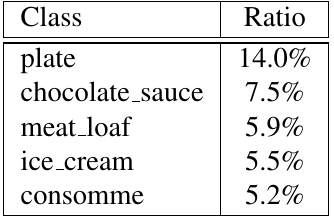
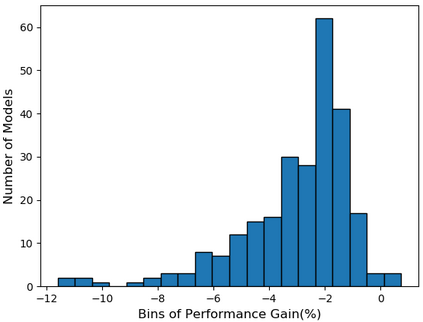
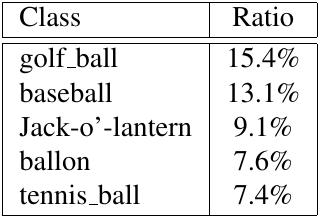
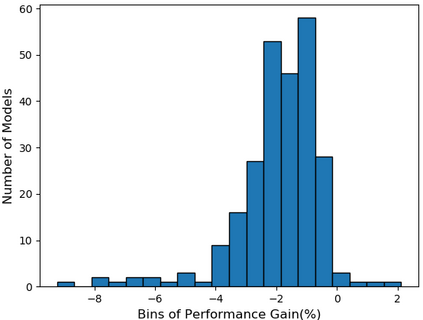
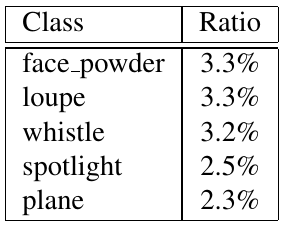
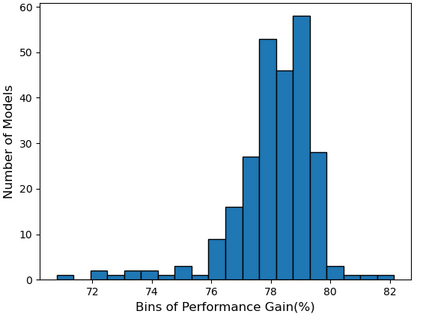
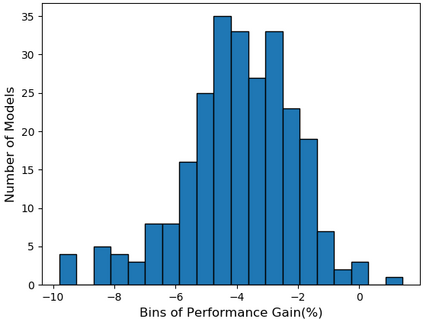
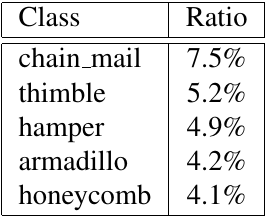
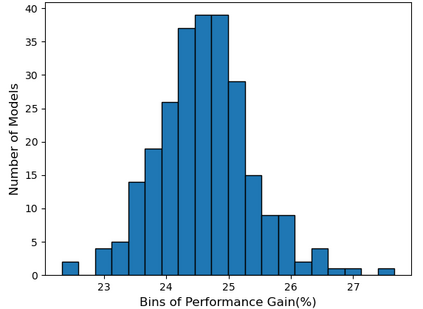
Self-supervised learning (SSL), especially contrastive methods, has raised attraction recently as it learns effective transferable representations without semantic annotations. A common practice for self-supervised pre-training is to use as much data as possible. For a specific downstream task, however, involving irrelevant data in pre-training may degenerate the downstream performance, observed from our extensive experiments. On the other hand, for existing SSL methods, it is burdensome and infeasible to use different downstream-task-customized datasets in pre-training for different tasks. To address this issue, we propose a novel SSL paradigm called Scalable Dynamic Routing (SDR), which can be trained once and deployed efficiently to different downstream tasks with task-customized pre-trained models. Specifically, we construct the SDRnet with various sub-nets and train each sub-net with only one subset of the data by data-aware progressive training. When a downstream task arrives, we route among all the pre-trained sub-nets to get the best along with its corresponding weights. Experiment results show that our SDR can train 256 sub-nets on ImageNet simultaneously, which provides better transfer performance than a unified model trained on the full ImageNet, achieving state-of-the-art (SOTA) averaged accuracy over 11 downstream classification tasks and AP on PASCAL VOC detection task.
翻译:自我监督学习(SSL),特别是对比性方法,最近随着学习有效的可转让表达形式而没有语义说明,提高了吸引力。自我监督培训前培训的常见做法是尽可能多地使用数据。然而,对于一项具体的下游任务,如从我们的广泛实验中观察到,涉及培训前不相关的数据,可能会降低下游业绩。另一方面,对于现有的SSL方法而言,在培训前的不同任务中使用不同的下游任务定制数据集是累赘和不可行的。为了解决这一问题,我们提议了一个叫作可缩放动态路由(SDR)的新型SSL模式,可以一次性培训,并有效地部署到不同下游任务中,采用任务定制的预先培训模式。具体地说,我们用各种子网构建SDRnet,用数据意识渐进式培训来培训每个子网,只有一组数据。当下游任务到来时,我们在所有经过培训的子网中选择了最佳的分网,以统一相应的重量。实验结果显示,我们的SDIS模型可以培训256次网络在图像网络上进行比经过培训的完整升级的图像网络升级的完整性工作,同时提供更好的甚甚高级的ASASAS-AS-AAS-AAS-PAAS-PAS-SAL AS-SAL AS-