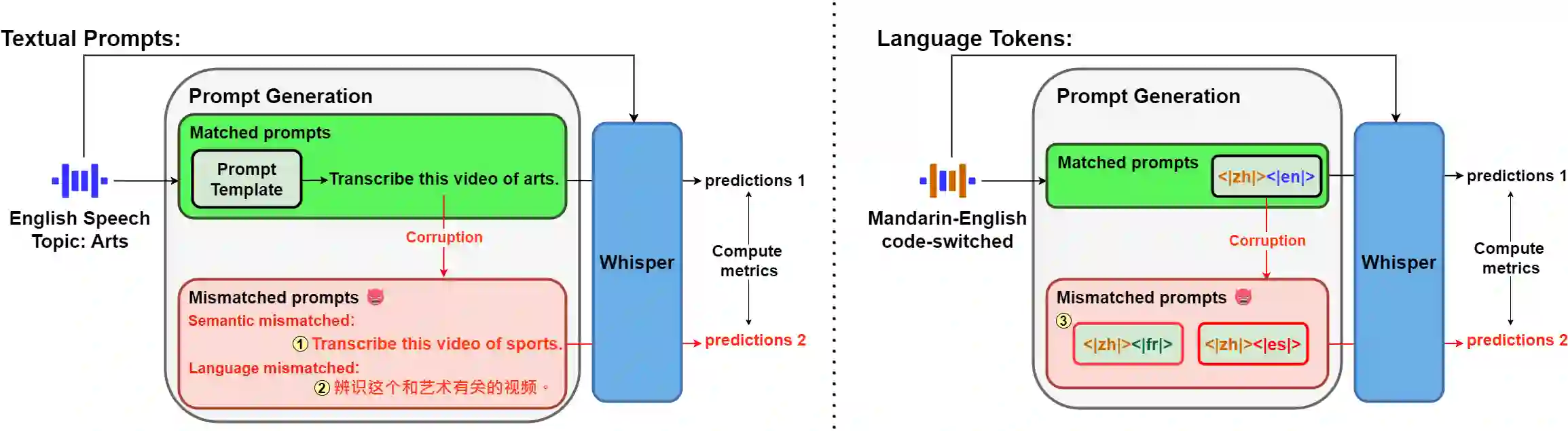
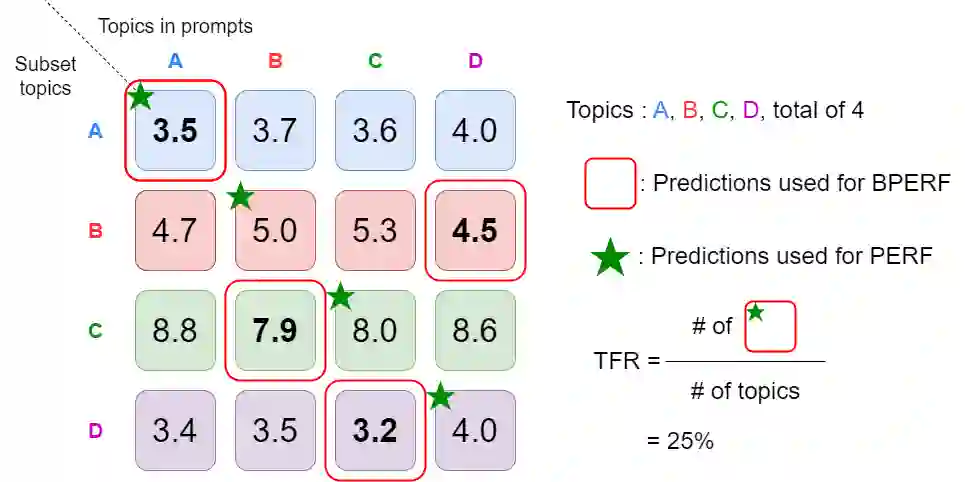
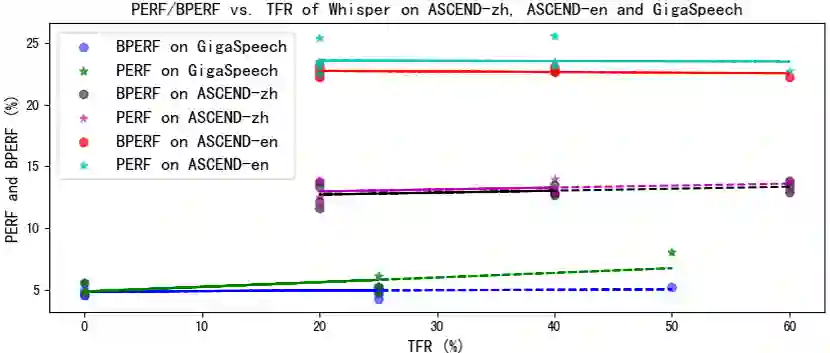
This research explores how the information of prompts interacts with the high-performing speech recognition model, Whisper. We compare its performances when prompted by prompts with correct information and those corrupted with incorrect information. Our results unexpectedly show that Whisper may not understand the textual prompts in a human-expected way. Additionally, we find that performance improvement is not guaranteed even with stronger adherence to the topic information in textual prompts. It is also noted that English prompts generally outperform Mandarin ones on datasets of both languages, likely due to differences in training data distributions for these languages despite the mismatch with pre-training scenarios. Conversely, we discover that Whisper exhibits awareness of misleading information in language tokens by ignoring incorrect language tokens and focusing on the correct ones. In sum, We raise insightful questions about Whisper's prompt understanding and reveal its counter-intuitive behaviors. We encourage further studies.
翻译:暂无翻译