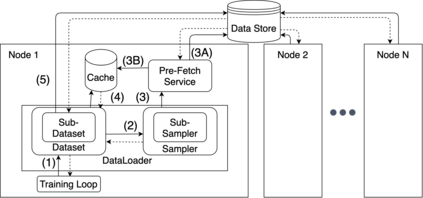
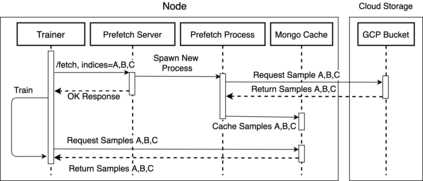
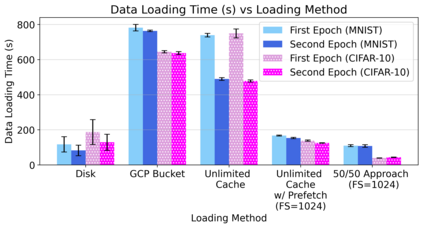
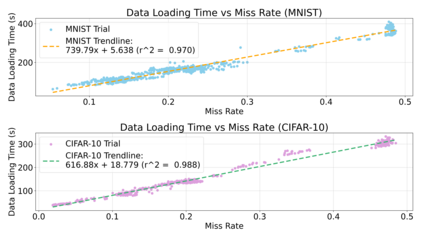
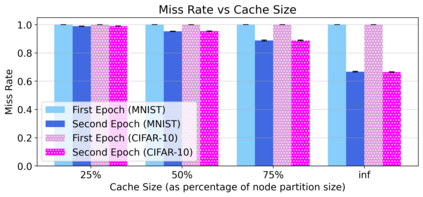
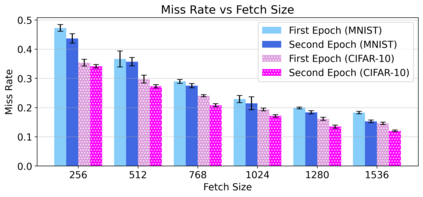
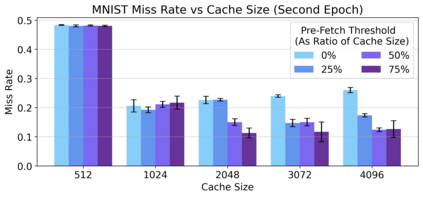
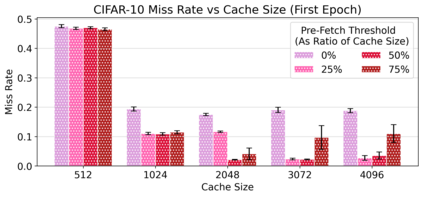
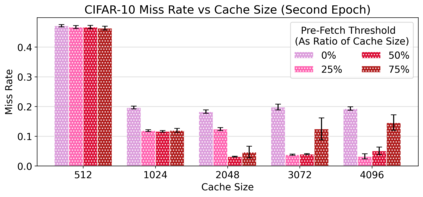
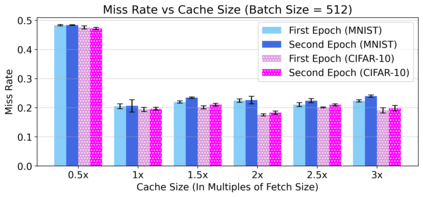
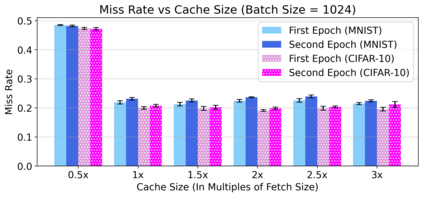
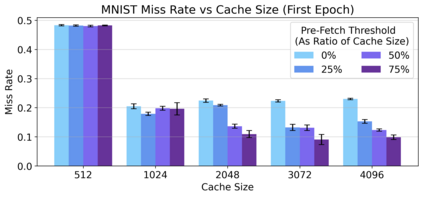
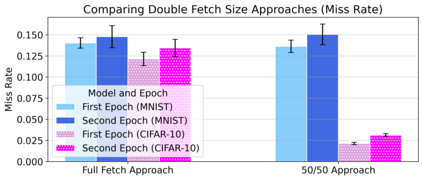
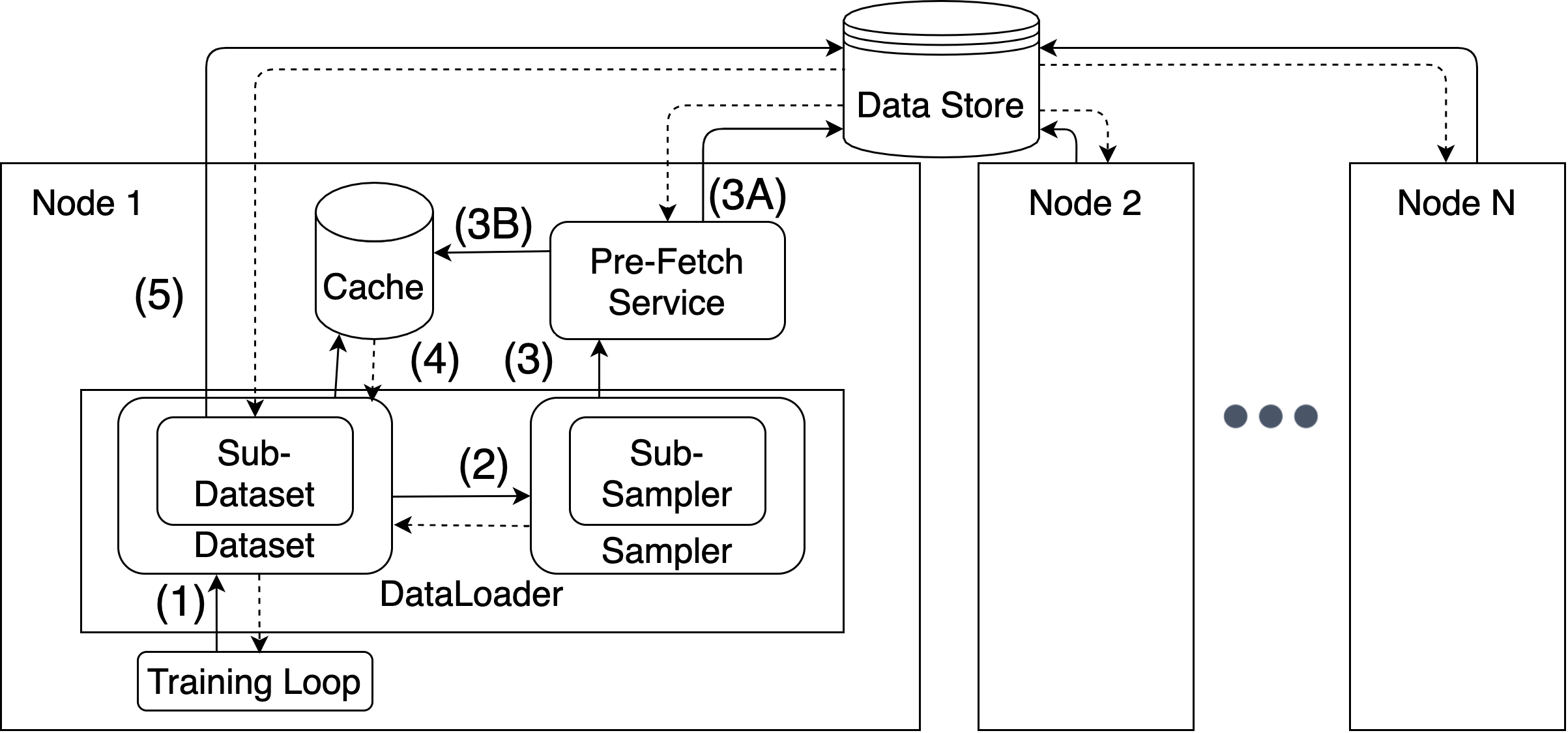
Cloud computing provides a powerful yet low-cost environment for distributed deep learning workloads. However, training complex deep learning models often requires accessing large amounts of data, which can easily exceed the capacity of local disks. Prior research often overlooks this training data problem by implicitly assuming that data is available locally or via low latency network-based data storage. Such implicit assumptions often do not hold in a cloud-based training environment, where deep learning practitioners create and tear down dedicated GPU clusters on demand, or do not have the luxury of local storage, such as in serverless workloads. In this work, we investigate the performance of distributed training that leverages training data residing entirely inside cloud storage buckets. These buckets promise low storage costs, but come with inherent bandwidth limitations that make them seem unsuitable for an efficient training solution. To account for these bandwidth limitations, we propose the use of two classical techniques, namely caching and pre-fetching, to mitigate the training performance degradation. We implement a prototype, DELI, based on the popular deep learning framework PyTorch by building on its data loading abstractions. We then evaluate the training performance of two deep learning workloads using Google Cloud's NVIDIA K80 GPU servers and show that we can reduce the time that the training loop is waiting for data by 85.6%-93.5% compared to loading directly from a storage bucket - thus achieving comparable performance to loading data directly from disk - while only storing a fraction of the data locally at a time. In addition, DELI has the potential of lowering the cost of running a training workload, especially on models with long per-epoch training times.
翻译:云层计算为分布式深层学习工作量提供了强大而低成本的环境。 但是,培训复杂的深层次学习模式往往需要获取大量数据,这些数据很容易超出本地磁盘的能力。 先前的研究往往隐含地假设数据是本地提供的,或通过低悬浮网络的数据储存,从而忽略了培训数据问题。 这些隐含的假设往往不存在于基于云层的培训环境中,因为深层次的学习实践者根据需求创建和拆除专门的GPU集群,或者没有当地存储的奢侈品,如服务器无服务器的工作量。 在这项工作中,我们调查了利用完全位于云层储存桶内的数据进行培训的绩效。 这些桶承诺了低存储成本,但带有内在的带宽限制,使得这些数据似乎不适合高效的培训解决方案。 为了说明这些带宽限制,我们建议使用两种传统技术,即缓冲和预展期技术,缓解培训绩效的退化。 我们根据广受欢迎的深层次学习框架,如在数据库中添加抽象数据,我们随后评估了两次深层次的培训绩效培训的绩效水平,在使用谷内服务器进行。