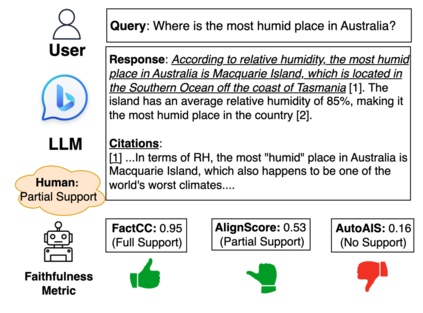
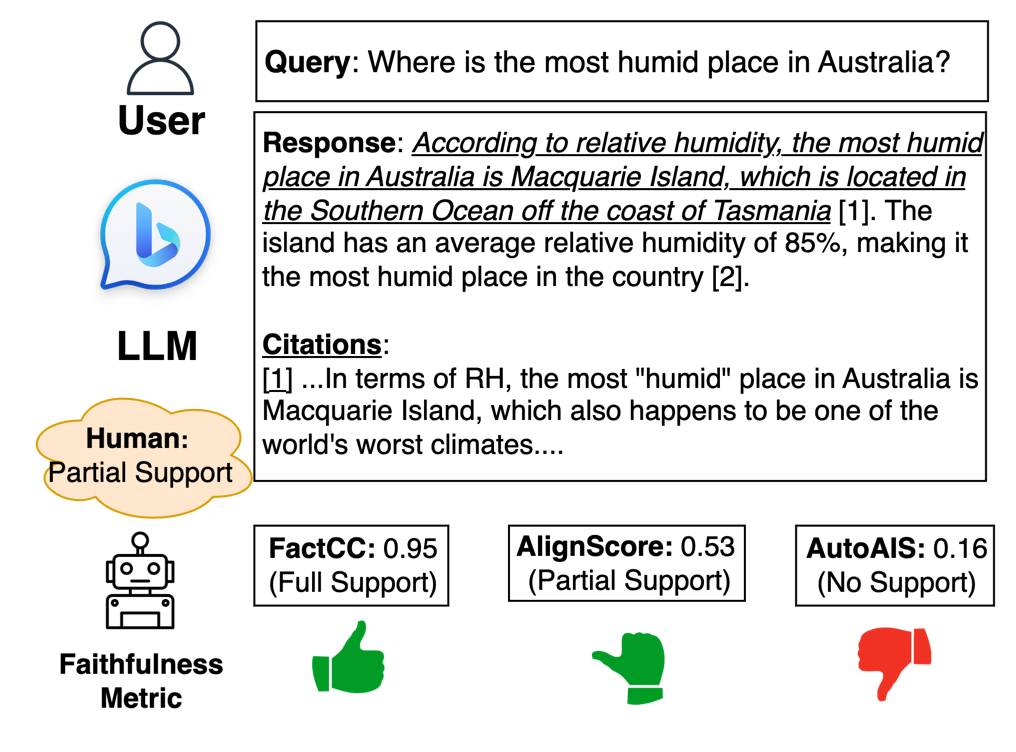
Large language models (LLMs) often produce unsupported or unverifiable information, known as "hallucinations." To mitigate this, retrieval-augmented LLMs incorporate citations, grounding the content in verifiable sources. Despite such developments, manually assessing how well a citation supports the associated statement remains a major challenge. Previous studies use faithfulness metrics to estimate citation support automatically but are limited to binary classification, overlooking fine-grained citation support in practical scenarios. To investigate the effectiveness of faithfulness metrics in fine-grained scenarios, we propose a comparative evaluation framework that assesses the metric effectiveness in distinguishinging citations between three-category support levels: full, partial, and no support. Our framework employs correlation analysis, classification evaluation, and retrieval evaluation to measure the alignment between metric scores and human judgments comprehensively. Our results show no single metric consistently excels across all evaluations, revealing the complexity of assessing fine-grained support. Based on the findings, we provide practical recommendations for developing more effective metrics.
翻译:暂无翻译