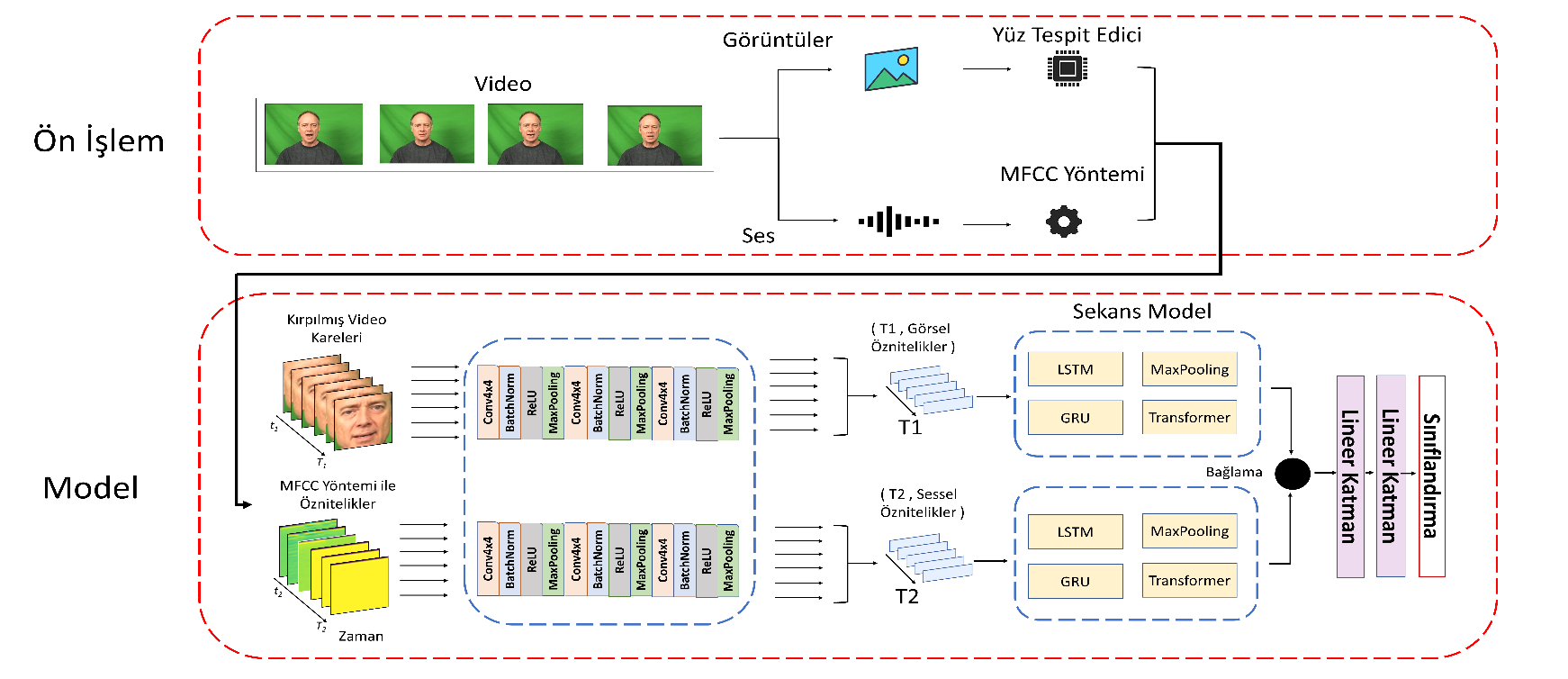
Emotion recognition has become an important research topic in the field of human-computer interaction. Studies on sound and videos to understand emotions focused mainly on analyzing facial expressions and classified 6 basic emotions. In this study, the performance of different sequence models in multi-modal emotion recognition was compared. The sound and images were first processed by multi-layered CNN models, and the outputs of these models were fed into various sequence models. The sequence model is GRU, Transformer, LSTM and Max Pooling. Accuracy, precision, and F1 Score values of all models were calculated. The multi-modal CREMA-D dataset was used in the experiments. As a result of the comparison of the CREMA-D dataset, GRU-based architecture with 0.640 showed the best result in F1 score, LSTM-based architecture with 0.699 in precision metric, while sensitivity showed the best results over time with Max Pooling-based architecture with 0.620. As a result, it has been observed that the sequence models compare performances close to each other.
翻译:暂无翻译