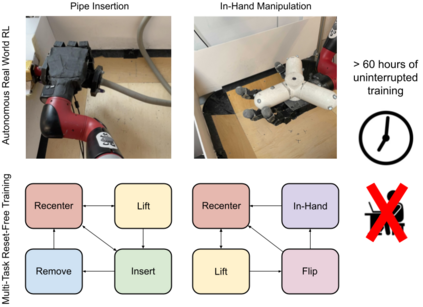
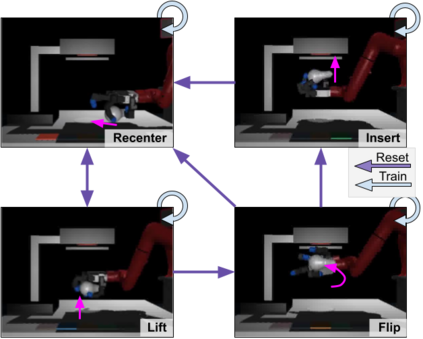
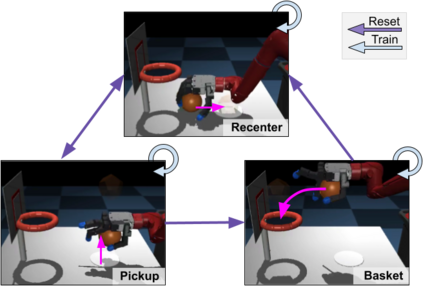
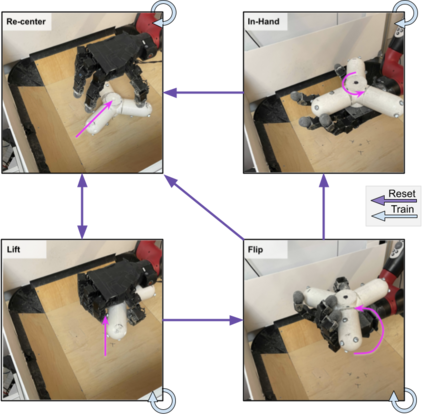
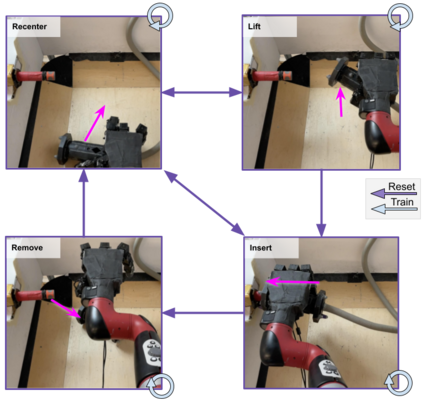
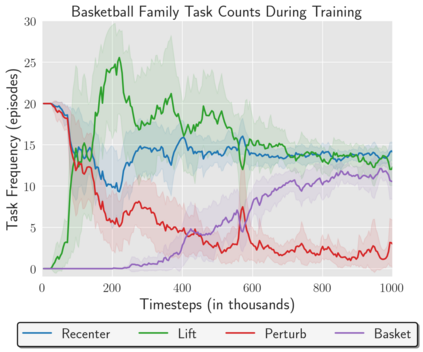
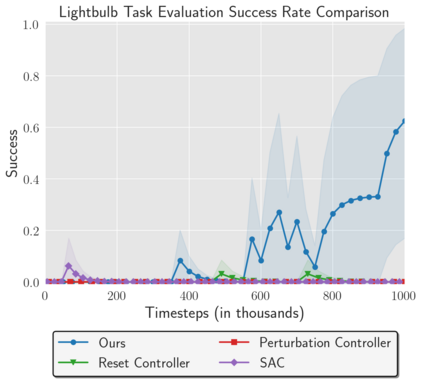
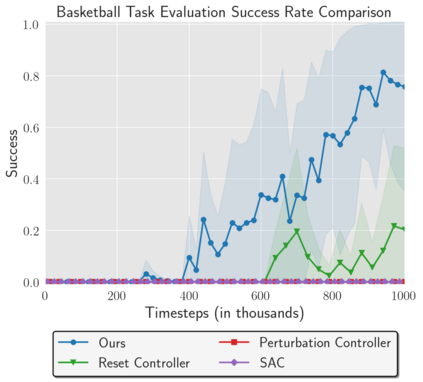
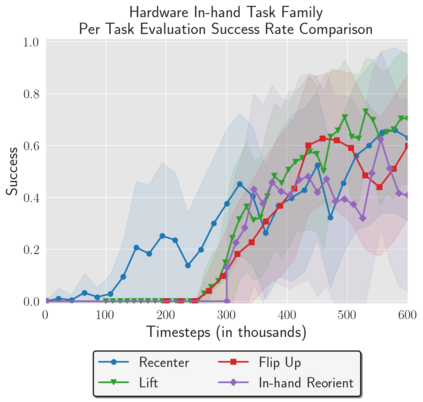
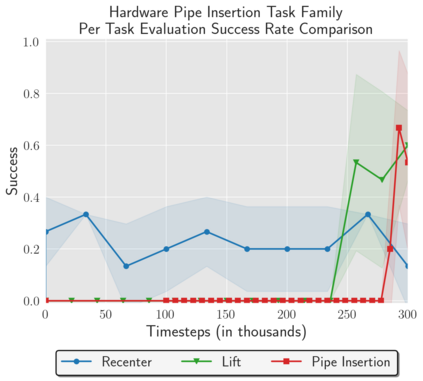
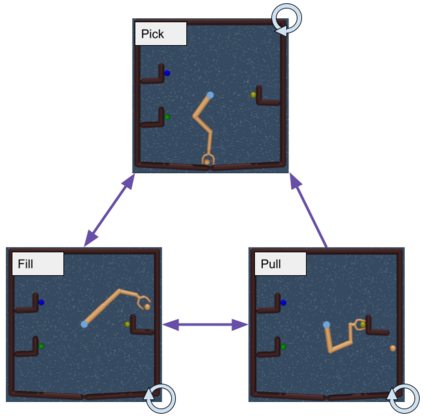
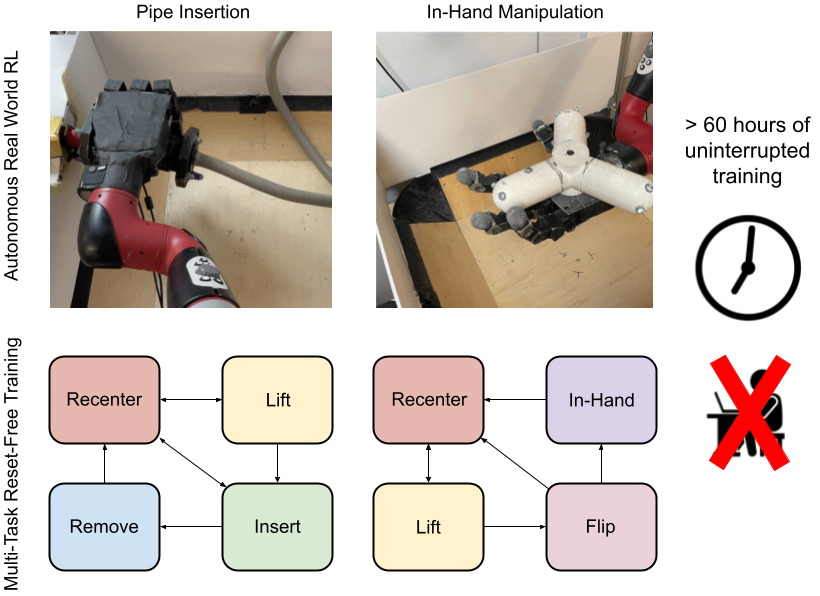
Reinforcement Learning (RL) algorithms can in principle acquire complex robotic skills by learning from large amounts of data in the real world, collected via trial and error. However, most RL algorithms use a carefully engineered setup in order to collect data, requiring human supervision and intervention to provide episodic resets. This is particularly evident in challenging robotics problems, such as dexterous manipulation. To make data collection scalable, such applications require reset-free algorithms that are able to learn autonomously, without explicit instrumentation or human intervention. Most prior work in this area handles single-task learning. However, we might also want robots that can perform large repertoires of skills. At first, this would appear to only make the problem harder. However, the key observation we make in this work is that an appropriately chosen multi-task RL setting actually alleviates the reset-free learning challenge, with minimal additional machinery required. In effect, solving a multi-task problem can directly solve the reset-free problem since different combinations of tasks can serve to perform resets for other tasks. By learning multiple tasks together and appropriately sequencing them, we can effectively learn all of the tasks together reset-free. This type of multi-task learning can effectively scale reset-free learning schemes to much more complex problems, as we demonstrate in our experiments. We propose a simple scheme for multi-task learning that tackles the reset-free learning problem, and show its effectiveness at learning to solve complex dexterous manipulation tasks in both hardware and simulation without any explicit resets. This work shows the ability to learn dexterous manipulation behaviors in the real world with RL without any human intervention.
翻译:原则上,强化学习(RL)算法可以通过从通过试验和错误收集的真实世界的大量数据中学习,获得复杂的机器人技能。然而,大多数RL算法都使用精心设计的设置来收集数据,需要人的监督和干预来提供后遗症。这在挑战机器人的问题中特别明显,例如dexterous 操纵。为了使数据收集能够缩放,这些应用需要重新设置的算法,这种算法能够自主地学习,而没有明确的仪器或人类干预。这个领域的大多数先前工作处理的是单任务学习。然而,我们也许也想要能够进行大量技能重组的机器人。首先,这似乎只会使问题变得更为棘手。然而,我们在这项工作中的主要观察是,一个选择得当的多任务设置的多任务设置实际上减轻了重置的学习挑战,而不需要什么额外的机械。事实上,解决多任务处理的任何重置的问题可以直接解决任何重置的问题,因为不同的任务组合可以用来完成其他任务的重置。通过学习多种任务,我们可以有效地学习多任务来重新学习,这样可以有效地学习多任务,从而重新学习更多的重修。