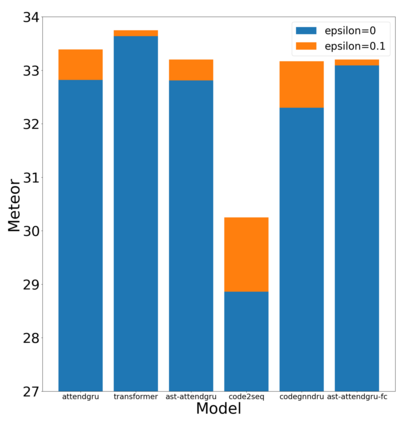
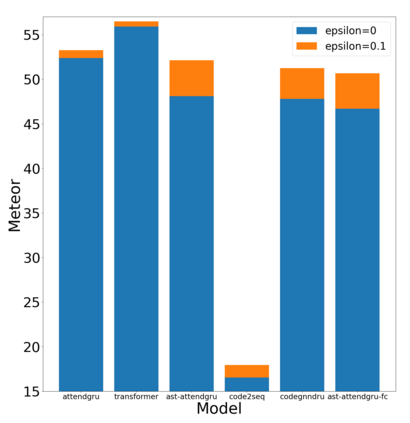
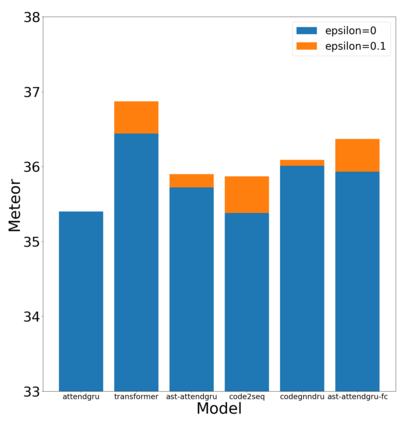
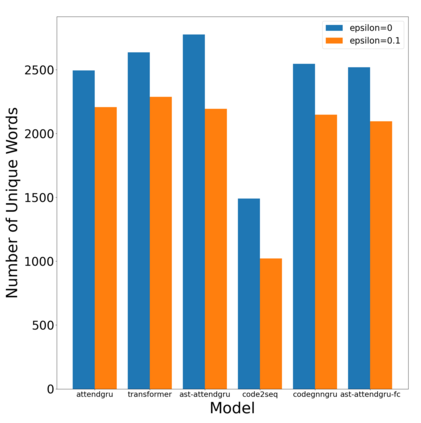
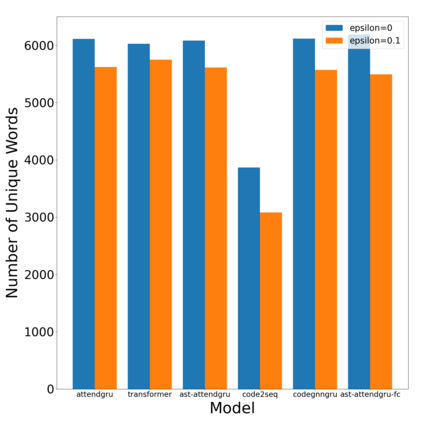
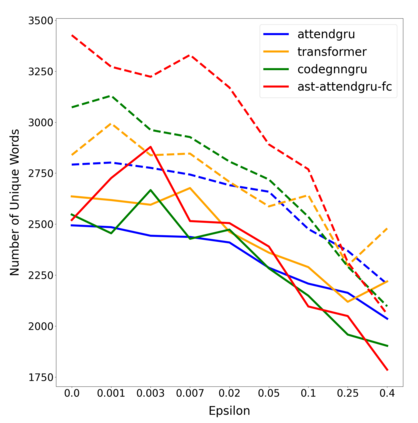
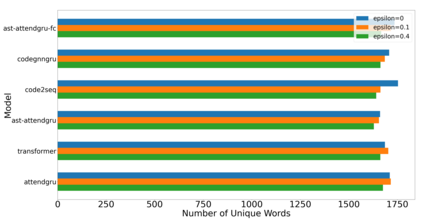
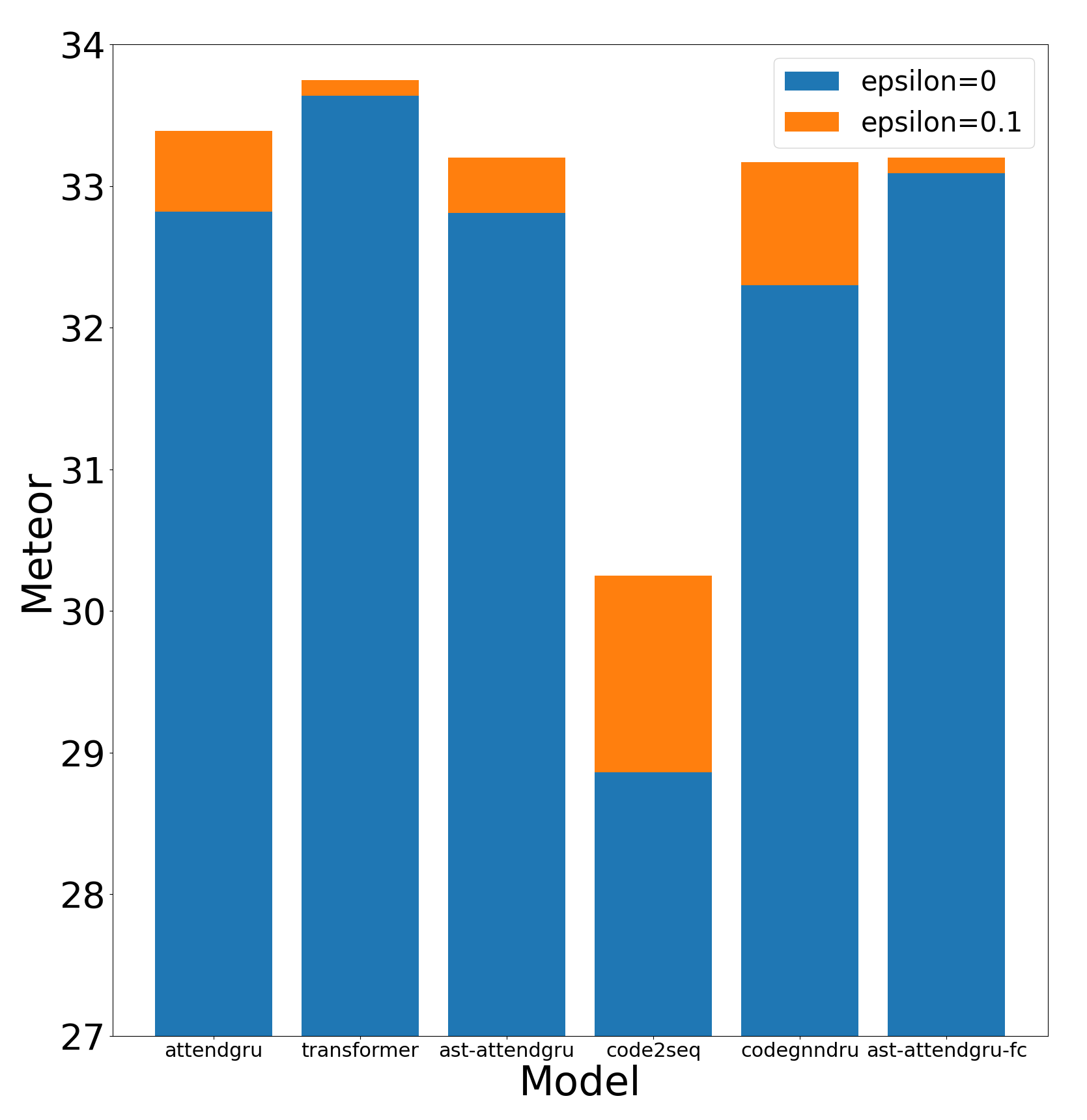
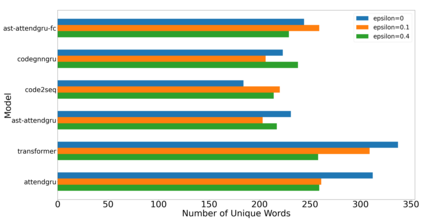Label smoothing is a regularization technique for neural networks. Normally neural models are trained to an output distribution that is a vector with a single 1 for the correct prediction, and 0 for all other elements. Label smoothing converts the correct prediction location to something slightly less than 1, then distributes the remainder to the other elements such that they are slightly greater than 0. A conceptual explanation behind label smoothing is that it helps prevent a neural model from becoming "overconfident" by forcing it to consider alternatives, even if only slightly. Label smoothing has been shown to help several areas of language generation, yet typically requires considerable tuning and testing to achieve the optimal results. This tuning and testing has not been reported for neural source code summarization - a growing research area in software engineering that seeks to generate natural language descriptions of source code behavior. In this paper, we demonstrate the effect of label smoothing on several baselines in neural code summarization, and conduct an experiment to find good parameters for label smoothing and make recommendations for its use.
翻译:标签平滑是一种神经网络的正则化技术。通常神经模型被训练成输出一个向量,其中只有一个元素是1,其它元素都是0。标签平滑将正确预测位置的值转换为略小于1的值,然后将剩下的部分分配给它们的它们的元素,这些元素略大于0。标签平滑的一个概念解释是帮助防止神经模型变得“过于自信”,强制其考虑备选项,即使只有微小的误差。标签平滑已被证明可以帮助多个语言生成领域,并且通常需要大量的调整和测试才能实现最优结果。这种调整和测试还没有报道在神经源代码摘要(一个旨在生成源代码行为的自然语言描述的软件工程领域中)上的效应。在这篇文章中,我们展示了标签平滑对神经代码摘要基准的影响,并进行了一项实验来寻找良好的标签平滑参数,并就其使用提出建议。