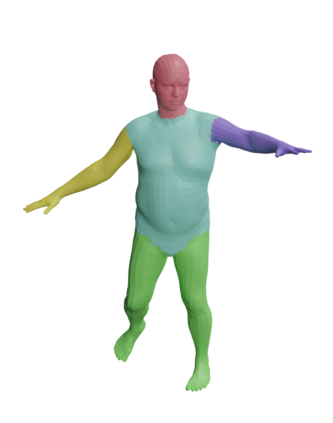
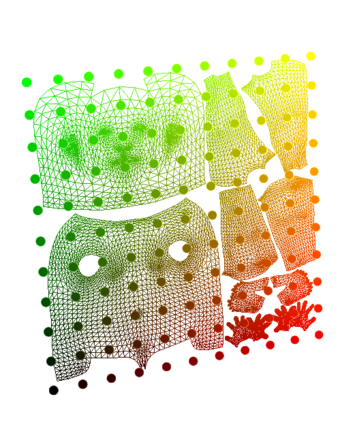
This paper addresses the challenge of quickly reconstructing free-viewpoint videos of dynamic humans from sparse multi-view videos. Some recent works represent the dynamic human as a canonical neural radiance field (NeRF) and a motion field, which are learned from videos through differentiable rendering. But the per-scene optimization generally requires hours. Other generalizable NeRF models leverage learned prior from datasets and reduce the optimization time by only finetuning on new scenes at the cost of visual fidelity. In this paper, we propose a novel method for learning neural volumetric videos of dynamic humans from sparse view videos in minutes with competitive visual quality. Specifically, we define a novel part-based voxelized human representation to better distribute the representational power of the network to different human parts. Furthermore, we propose a novel 2D motion parameterization scheme to increase the convergence rate of deformation field learning. Experiments demonstrate that our model can be learned 100 times faster than prior per-scene optimization methods while being competitive in the rendering quality. Training our model on a $512 \times 512$ video with 100 frames typically takes about 5 minutes on a single RTX 3090 GPU. The code will be released on our $\href{https://zju3dv.github.io/instant_nvr}{project~page}$.
翻译:本文讨论了快速重建由稀有多视图视频提供的动态人类自由视野视频的挑战。 近期的一些作品代表了动态人类, 是一个有活力人类的康纳神经光亮场和一个运动场, 通过不同的图像学习。 但是, perscene 优化通常需要几个小时。 其它一般的 NeRF 模型利用了先前从数据集中学习的优势, 并且仅以视觉忠诚为代价微调新场景, 从而减少优化时间。 在本文中, 我们提出了一个创新的方法, 用于学习动态人类的神经体积视频, 在有竞争性视觉质量的几分钟里学习。 具体地说, 我们定义了一个新型的基于部分合成人类的人类代表, 以更好地将网络的代表能力传播到不同的人类部分。 此外, 我们提出了一个新的 2D 运动参数化方案, 以提高变形场学习的趋同率。 实验表明, 我们的模型可以比先前的每台平价更快100倍地学习, 同时在质量上更具有竞争力。 培训我们的模型, 512\time 人类的512美元视频, 用100个框架 通常需要5分钟。 GMXxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx