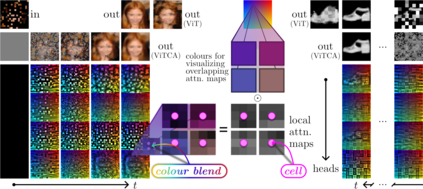
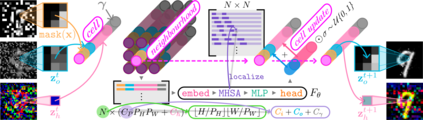
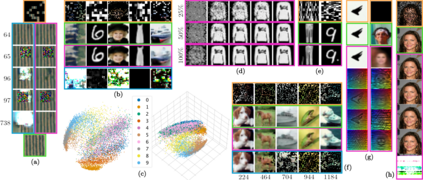
Recent extensions of Cellular Automata (CA) have incorporated key ideas from modern deep learning, dramatically extending their capabilities and catalyzing a new family of Neural Cellular Automata (NCA) techniques. Inspired by Transformer-based architectures, our work presents a new class of $\textit{attention-based}$ NCAs formed using a spatially localized$\unicode{x2014}$yet globally organized$\unicode{x2014}$self-attention scheme. We introduce an instance of this class named $\textit{Vision Transformer Cellular Automata}$ (ViTCA). We present quantitative and qualitative results on denoising autoencoding across six benchmark datasets, comparing ViTCA to a U-Net, a U-Net-based CA baseline (UNetCA), and a Vision Transformer (ViT). When comparing across architectures configured to similar parameter complexity, ViTCA architectures yield superior performance across all benchmarks and for nearly every evaluation metric. We present an ablation study on various architectural configurations of ViTCA, an analysis of its effect on cell states, and an investigation on its inductive biases. Finally, we examine its learned representations via linear probes on its converged cell state hidden representations, yielding, on average, superior results when compared to our U-Net, ViT, and UNetCA baselines.
翻译:细胞自动数据( CA) 最近的扩展包含了现代深层学习的关键理念, 大大扩展了它们的能力并催化了神经细胞自动分析技术( NCA) 。 在基于变压器的架构的启发下, 我们的工作展示了一个新的类别, 即以空间本地化$\ unicode{x2014}$yt, 全球有组织$\unicode{x2014}$自备计划构成的NCA 。 我们引入了一个名为 $\ textit{ Vision 变换机自动数据组$( VICTA) 的例子。 我们展示了六个基准数据集自动解密的定量和定性结果, 将 VICA 与 U-Net 基数比较, U-Net CA 基线(UNetCA) 和 Vivision Tranger (VITA) 计划。 当将配置的跨结构与相似的参数复杂度进行比较时, VICT 结构在所有基准和几乎每个评价指标中都产生优优异性业绩。 我们展示了VTCA 的各种建筑结构配置配置配置配置配置配置,,, 最终分析了 VICABA 的图像分析, 和我们所 的深度分析。