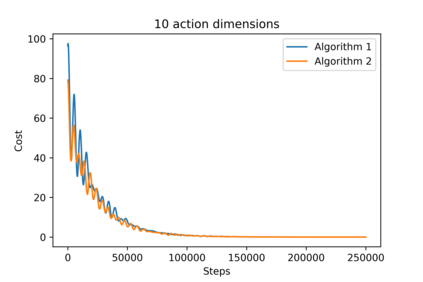
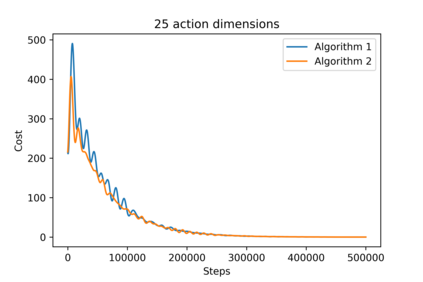
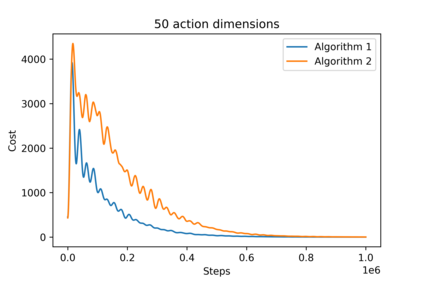
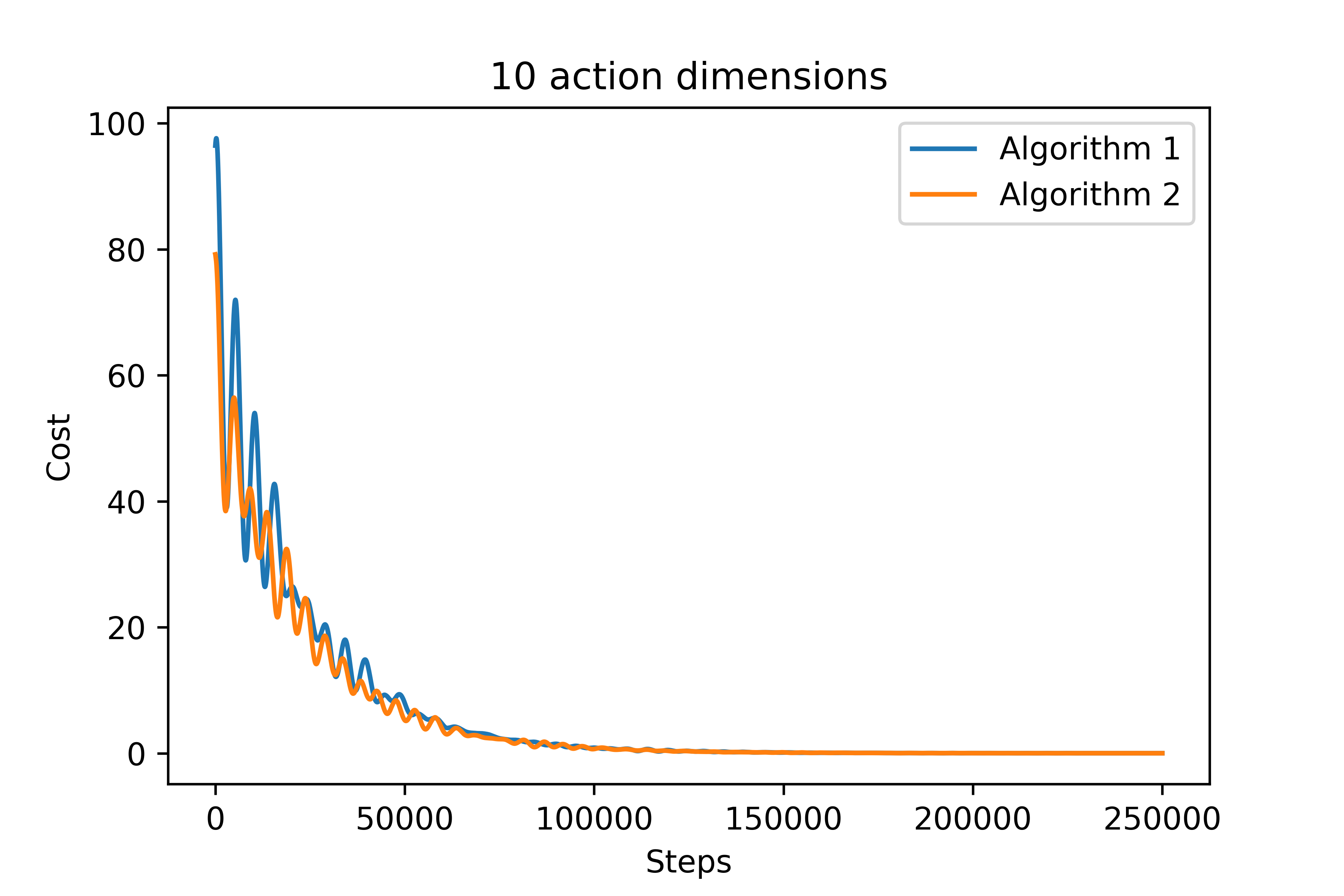
[Zhang, ICML 2018] provided the first decentralized actor-critic algorithm for multi-agent reinforcement learning (MARL) that offers convergence guarantees. In that work, policies are stochastic and are defined on finite action spaces. We extend those results to offer a provably-convergent decentralized actor-critic algorithm for learning deterministic policies on continuous action spaces. Deterministic policies are important in real-world settings. To handle the lack of exploration inherent in deterministic policies, we consider both off-policy and on-policy settings. We provide the expression of a local deterministic policy gradient, decentralized deterministic actor-critic algorithms and convergence guarantees for linearly-approximated value functions. This work will help enable decentralized MARL in high-dimensional action spaces and pave the way for more widespread use of MARL.
翻译:[张,ICML 2018] 提供了第一个为多试剂强化学习提供融合保障的分散化的行为者-批评算法(MARL),在这项工作中,政策是随机的,是在有限的行动空间上界定的。我们扩大这些结果,为学习关于持续行动空间的确定性政策提供了一种可辨别的分散化的行为者-批评算法。在现实世界环境中,确定性政策很重要。为了处理确定性政策所固有的缺乏探索的问题,我们既考虑政策外的,也考虑政策上的设置。我们为线性近值功能提供了一种地方确定性政策梯度、分散化的确定性行为者-批评算法和趋同保证的表达方式。这项工作将有助于使分散化的MARL能够在高维行动空间进行,并为更广泛地使用MARL铺平道路。