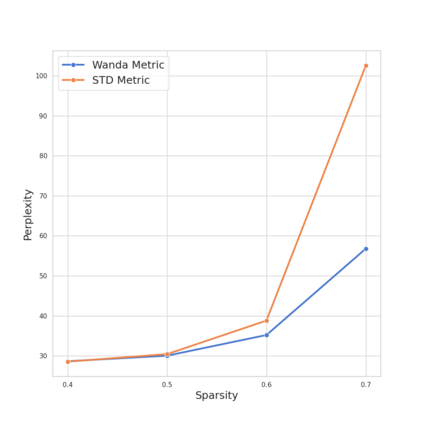
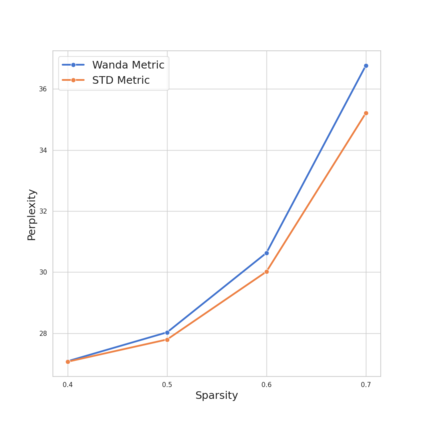
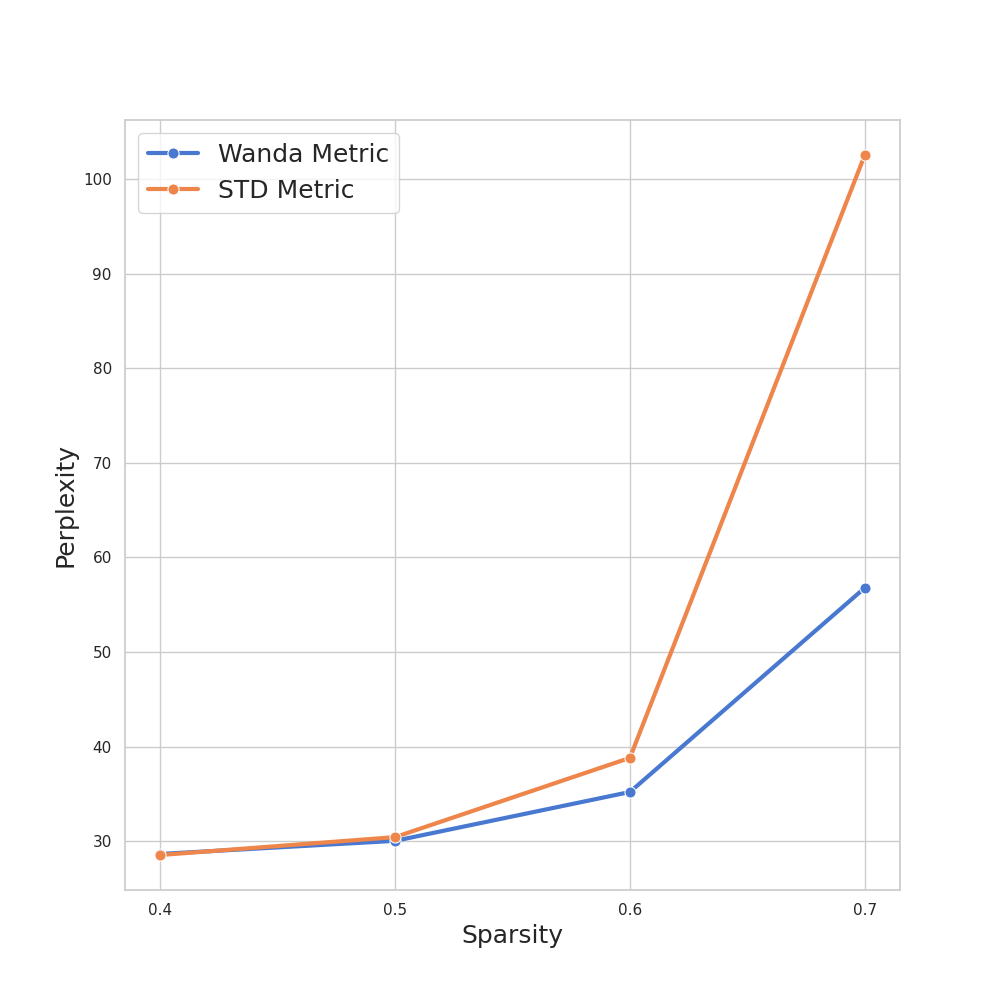
Recently, Large Language Models (LLMs) have become very widespread and are used to solve a wide variety of tasks. To successfully handle these tasks, LLMs require longer training times and larger model sizes. This makes LLMs ideal candidates for pruning methods that reduce computational demands while maintaining performance. Previous methods require a retraining phase after pruning to maintain the original model's performance. However, state-of-the-art pruning methods, such as Wanda, prune the model without retraining, making the pruning process faster and more efficient. Building upon Wanda's work, this study provides a theoretical explanation of why the method is effective and leverages these insights to enhance the pruning process. Specifically, a theoretical analysis of the pruning problem reveals a common scenario in Machine Learning where Wanda is the optimal pruning method. Furthermore, this analysis is extended to cases where Wanda is no longer optimal, leading to the development of a new method, STADE, based on the standard deviation of the input. From a theoretical standpoint, STADE demonstrates better generality across different scenarios. Finally, extensive experiments on Llama and Open Pre-trained Transformers (OPT) models validate these theoretical findings, showing that depending on the training conditions, Wanda's optimal performance varies as predicted by the theoretical framework. These insights contribute to a more robust understanding of pruning strategies and their practical implications. Code is available at: https://github.com/Coello-dev/STADE/
翻译:暂无翻译