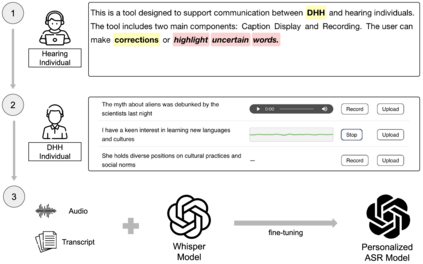
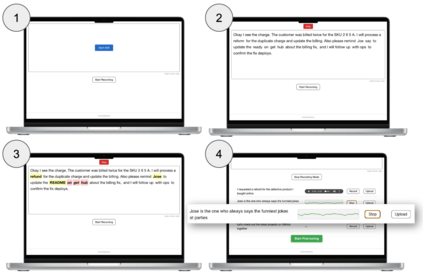
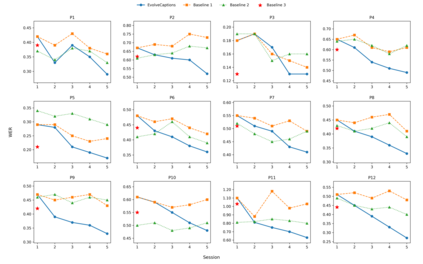
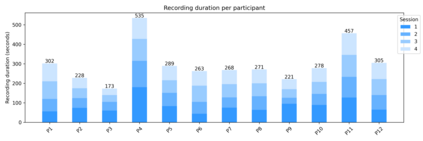
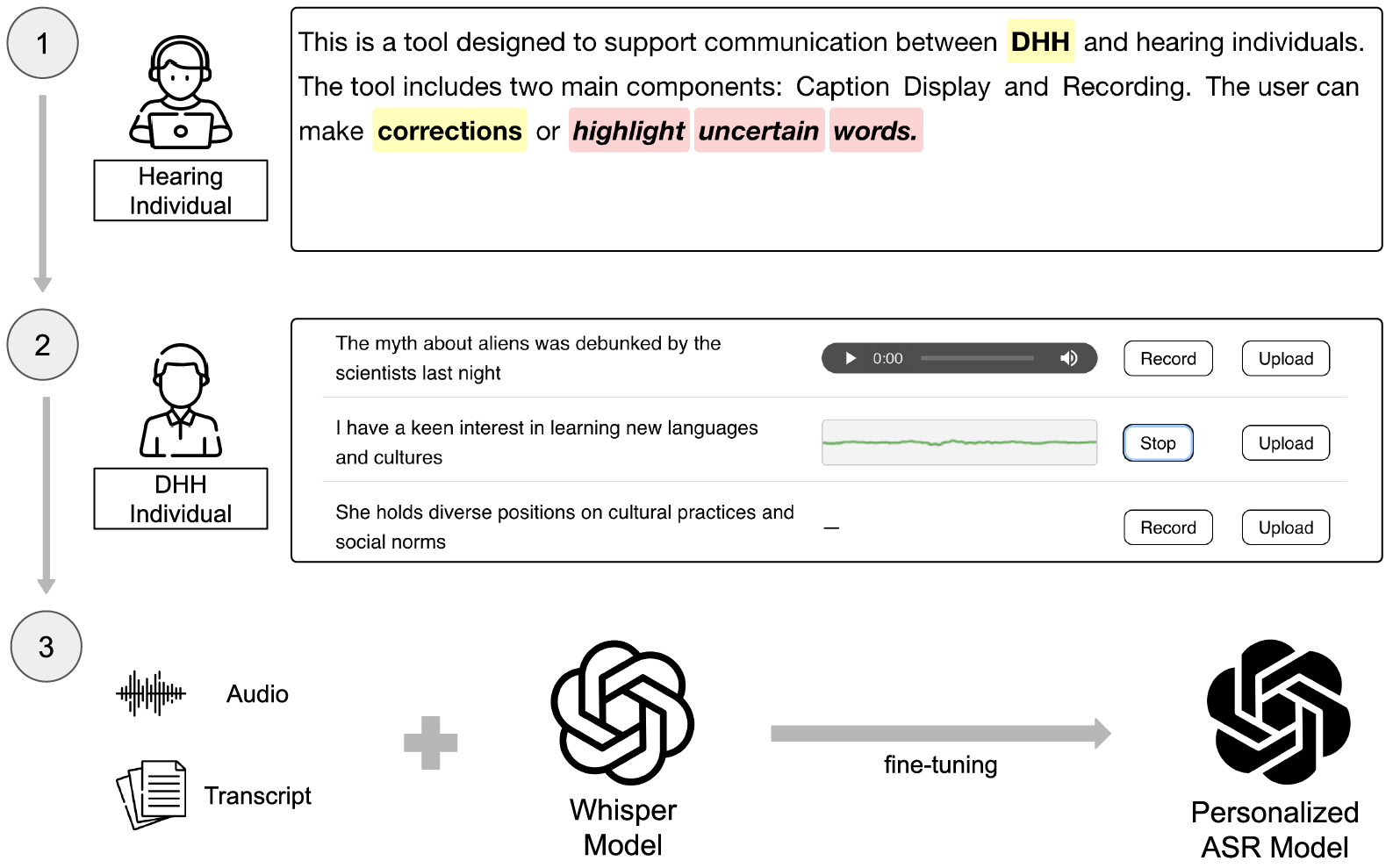
Automatic Speech Recognition (ASR) systems often fail to accurately transcribe speech from Deaf and Hard of Hearing (DHH) individuals, especially during real-time conversations. Existing personalization approaches typically require extensive pre-recorded data and place the burden of adaptation on the DHH speaker. We present EvolveCaptions, a real-time, collaborative ASR adaptation system that supports in-situ personalization with minimal effort. Hearing participants correct ASR errors during live conversations. Based on these corrections, the system generates short, phonetically targeted prompts for the DHH speaker to record, which are then used to fine-tune the ASR model. In a study with 12 DHH and six hearing participants, EvolveCaptions reduced Word Error Rate (WER) across all DHH users within one hour of use, using only five minutes of recording time on average. Participants described the system as intuitive, low-effort, and well-integrated into communication. These findings demonstrate the promise of collaborative, real-time ASR adaptation for more equitable communication.
翻译:暂无翻译