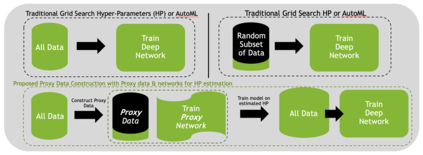
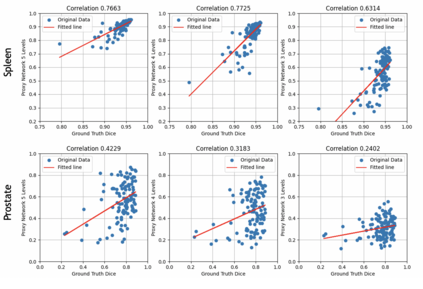
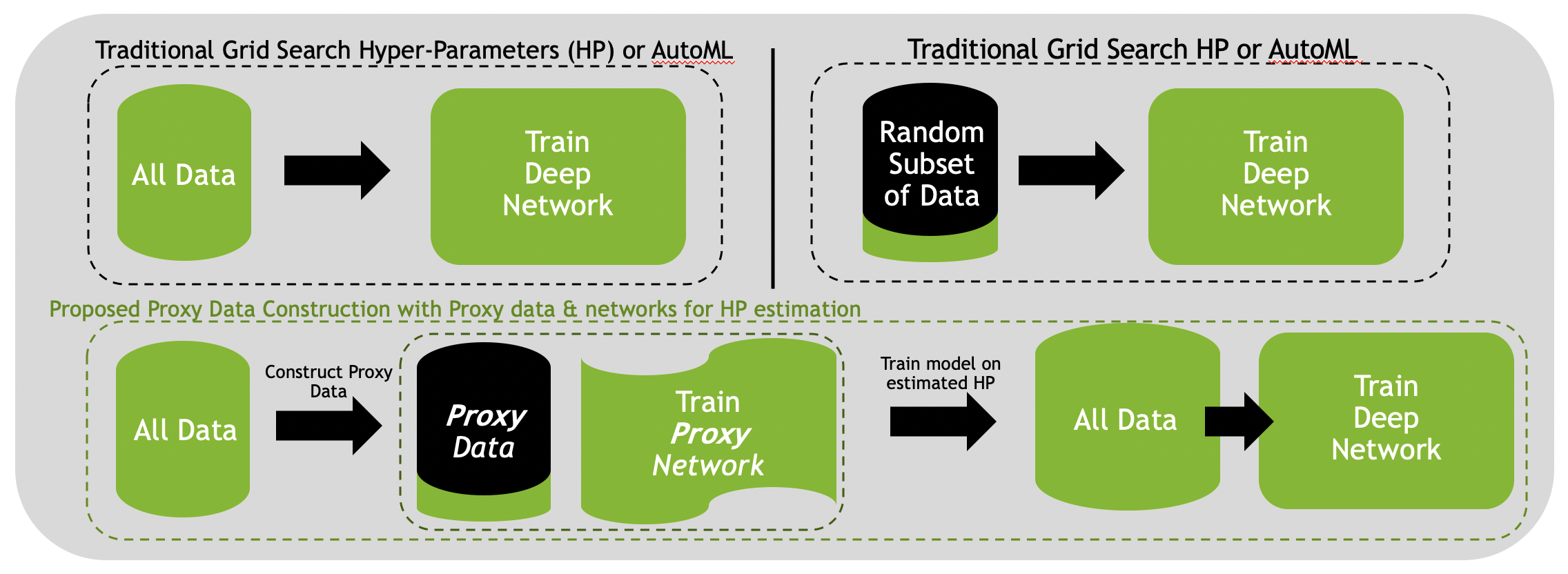
Deep learning models for medical image segmentation are primarily data-driven. Models trained with more data lead to improved performance and generalizability. However, training is a computationally expensive process because multiple hyper-parameters need to be tested to find the optimal setting for best performance. In this work, we focus on accelerating the estimation of hyper-parameters by proposing two novel methodologies: proxy data and proxy networks. Both can be useful for estimating hyper-parameters more efficiently. We test the proposed techniques on CT and MR imaging modalities using well-known public datasets. In both cases using one dataset for building proxy data and another data source for external evaluation. For CT, the approach is tested on spleen segmentation with two datasets. The first dataset is from the medical segmentation decathlon (MSD), where the proxy data is constructed, the secondary dataset is utilized as an external validation dataset. Similarly, for MR, the approach is evaluated on prostate segmentation where the first dataset is from MSD and the second dataset is PROSTATEx. First, we show higher correlation to using full data for training when testing on the external validation set using smaller proxy data than a random selection of the proxy data. Second, we show that a high correlation exists for proxy networks when compared with the full network on validation Dice score. Third, we show that the proposed approach of utilizing a proxy network can speed up an AutoML framework for hyper-parameter search by 3.3x, and by 4.4x if proxy data and proxy network are utilized together.
翻译:用于医学图像分解的深度学习模型主要是数据驱动的。经过更多数据培训的模型可以提高性能和一般性能。但是,培训是一个计算成本昂贵的过程,因为需要用多个超参数测试,才能找到最佳性能的最佳设置。在这项工作中,我们的重点是通过提出两种新颖方法来加速对超参数的估计:代理数据和代理网络。两者都可用于更高效地估计超参数。我们用众所周知的公共数据集测试拟议的CT和MR成像模式的技术。在这两种情况下,使用一个数据集来建立代理数据,另一个数据源用于外部评价。对于CT,该方法需要用两个数据集在胸膜分解上测试。在构建代理数据所在的医学分解 Decathlon (MSD) 中,我们侧重于加速对超高参数的估算。对于MRM(MR)来说,我们用前状态分解方法来评估第一组数据集来自MSD,第二个数据集是PROSTATEx。首先,我们用更高级的关联性关系来使用完全的代理性数据,当我们用来测试外部数据定值网络时,我们用一个高级的DNA网络来测试时,我们用一个自动流流流数据分解数据分解数据分解数据分解。