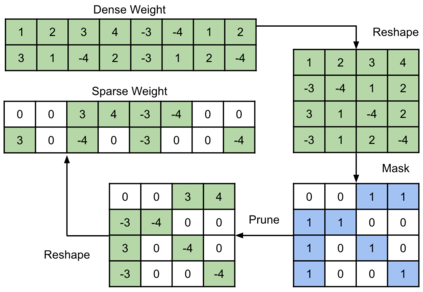
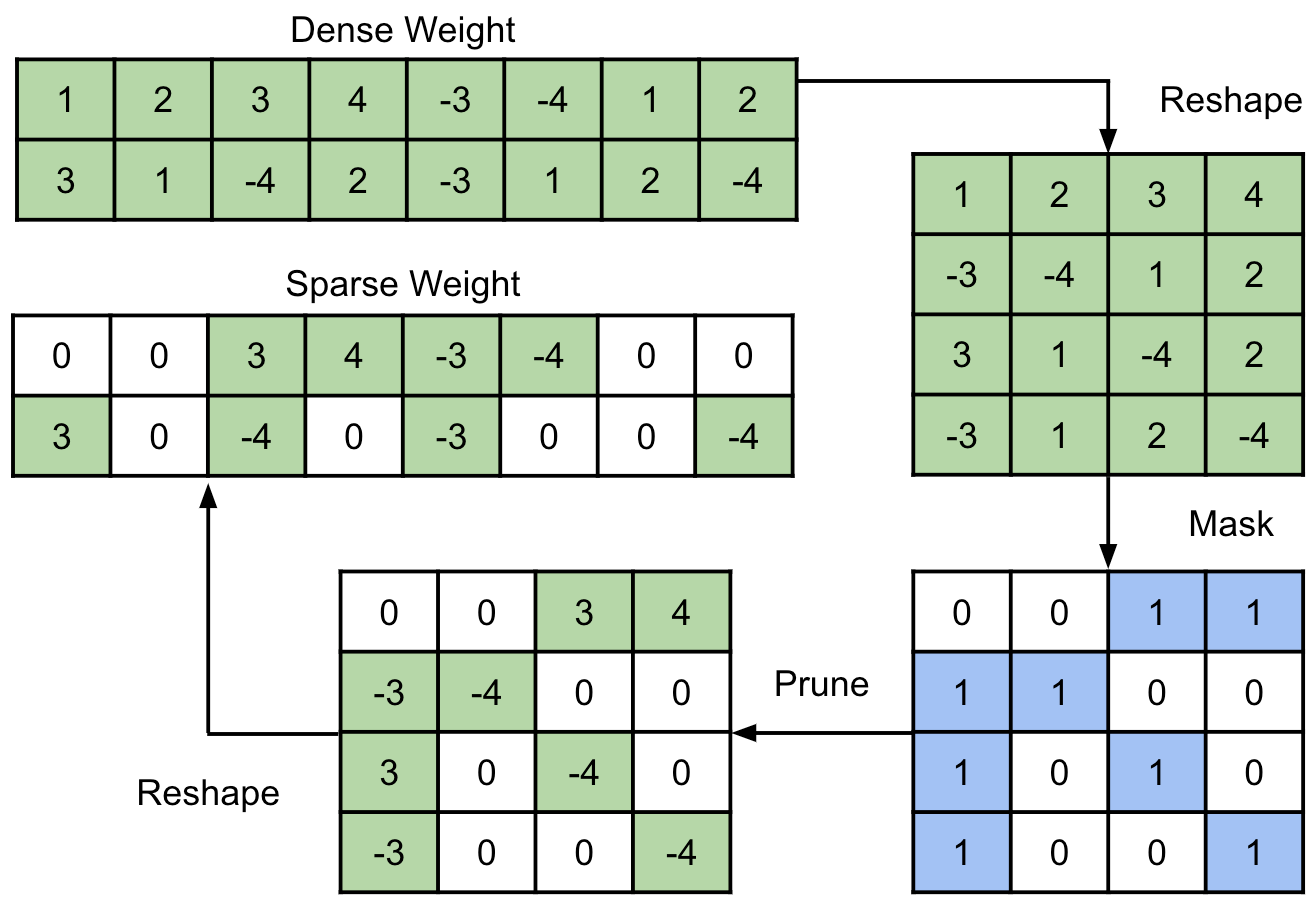
End-to-end automatic speech recognition (ASR) models have seen revolutionary quality gains with the recent development of large-scale universal speech models (USM). However, deploying these massive USMs is extremely expensive due to the enormous memory usage and computational cost. Therefore, model compression is an important research topic to fit USM-based ASR under budget in real-world scenarios. In this study, we propose a USM fine-tuning approach for ASR, with a low-bit quantization and N:M structured sparsity aware paradigm on the model weights, reducing the model complexity from parameter precision and matrix topology perspectives. We conducted extensive experiments with a 2-billion parameter USM on a large-scale voice search dataset to evaluate our proposed method. A series of ablation studies validate the effectiveness of up to int4 quantization and 2:4 sparsity. However, a single compression technique fails to recover the performance well under extreme setups including int2 quantization and 1:4 sparsity. By contrast, our proposed method can compress the model to have 9.4% of the size, at the cost of only 7.3% relative word error rate (WER) regressions. We also provided in-depth analyses on the results and discussions on the limitations and potential solutions, which would be valuable for future studies.
翻译:暂无翻译