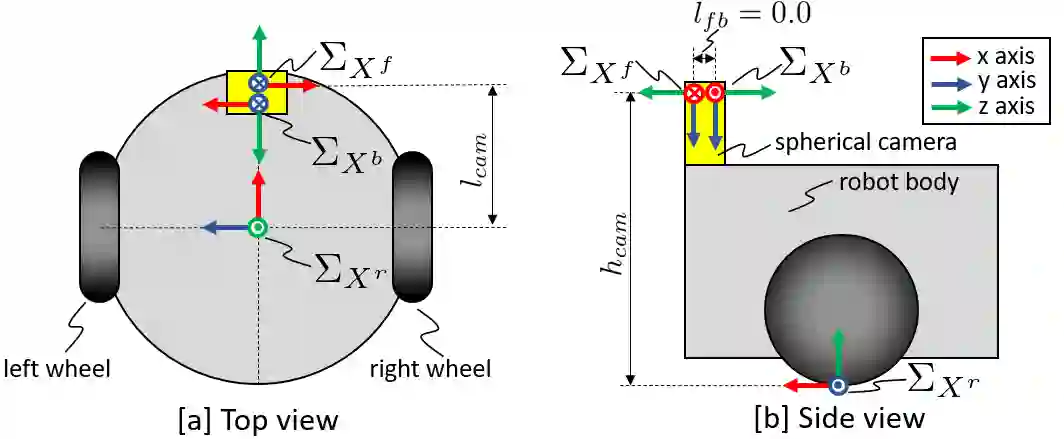
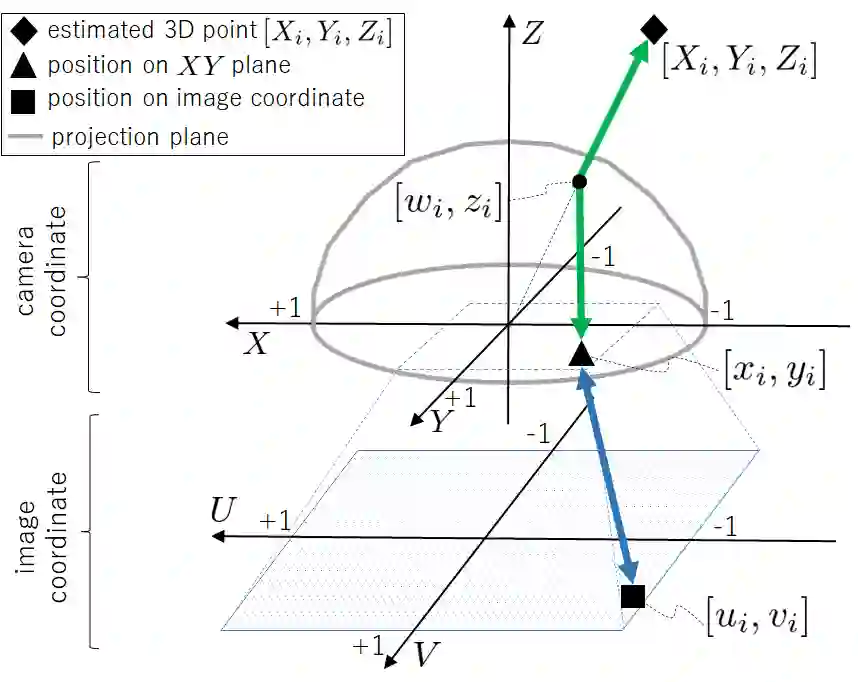
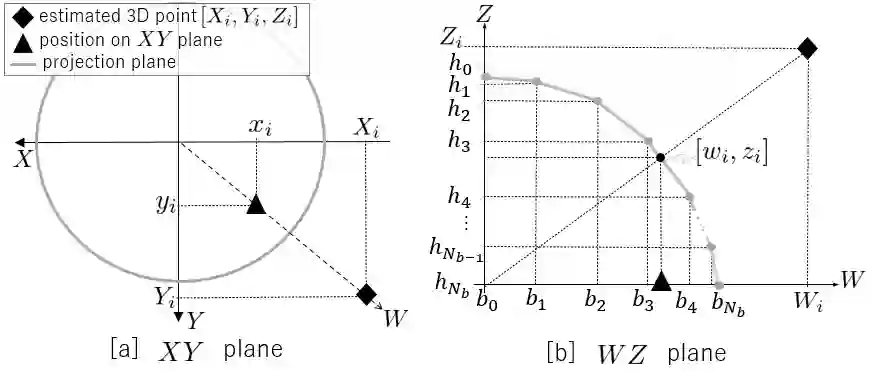
Self-supervised monocular depth estimation has been widely investigated to estimate depth images and relative poses from RGB images. This framework is attractive for researchers because the depth and pose networks can be trained from just time sequence images without the need for the ground truth depth and poses. In this work, we estimate the depth around a robot (360 degree view) using time sequence spherical camera images, from a camera whose parameters are unknown. We propose a learnable axisymmetric camera model which accepts distorted spherical camera images with two fisheye camera images. In addition, we trained our models with a photo-realistic simulator to generate ground truth depth images to provide supervision. Moreover, we introduced loss functions to provide floor constraints to reduce artifacts that can result from reflective floor surfaces. We demonstrate the efficacy of our method using the spherical camera images from the GO Stanford dataset and pinhole camera images from the KITTI dataset to compare our method's performance with that of baseline method in learning the camera parameters.
翻译:自我监督的单眼深度估计已经得到广泛调查,以估计深度图像和RGB图像的相对面貌。 这个框架对研究人员很有吸引力, 因为深度和构成网络可以通过仅仅时间序列图像来训练, 而不需要地面真相深度和配置。 在这项工作中, 我们用时间序列球形相机图像来估计机器人周围的深度( 360度视图), 其参数未知的相机。 我们提出了一个可学习的轴心摄影机模型, 接受有两张鱼眼相机图像的扭曲球形相机图像。 此外, 我们用摄影现实模拟器来训练我们的模型, 以生成地面真相深度图像来提供监督。 此外, 我们引入了损失功能, 提供地面限制, 以减少反射地面表面产生的文物。 我们用GO Stanford数据集的球形相机图像和KITTI数据集的插孔相机图像来展示我们的方法的功效, 来比较我们方法的性能和学习相机参数的基准方法的性能。