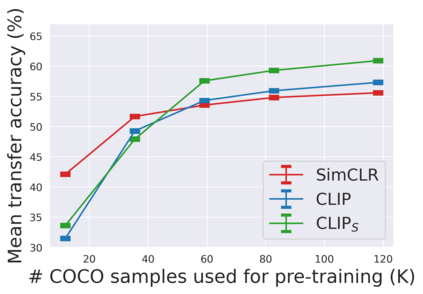
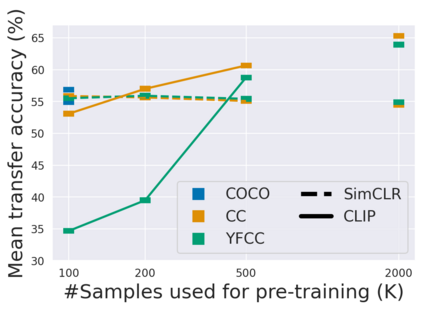
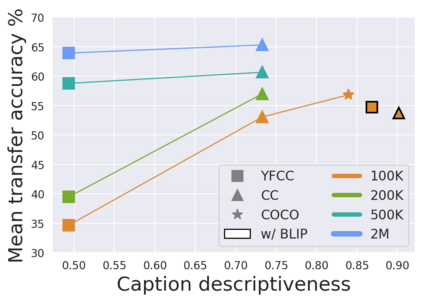
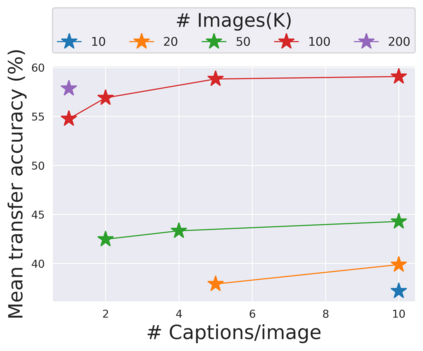
The development of CLIP [Radford et al., 2021] has sparked a debate on whether language supervision can result in vision models with more transferable representations than traditional image-only methods. Our work studies this question through a carefully controlled comparison of two approaches in terms of their ability to learn representations that generalize to downstream classification tasks. We find that when the pre-training dataset meets certain criteria -- it is sufficiently large and contains descriptive captions with low variability -- image-only methods do not match CLIP's transfer performance, even when they are trained with more image data. However, contrary to what one might expect, there are practical settings in which these criteria are not met, wherein added supervision through captions is actually detrimental. Motivated by our findings, we devise simple prescriptions to enable CLIP to better leverage the language information present in existing pre-training datasets.
翻译:发展CLIP[Radford等人,2021]已经引发了一场辩论,讨论语言监督是否能够产生比传统的只显示图像的方法更具有可转移性的形象模型。我们的工作研究是通过仔细控制地比较两种方法来研究这一问题,即它们是否有能力学习概括到下游分类任务的表述。我们发现,当培训前数据集达到某些标准时 -- -- 它足够大,含有低变异性的描述性说明 -- -- 仅显示图像的方法与CLIP的传输性能不匹配,即使它们受过更多的图像数据的培训。然而,与人们可能期望的相反,有些实际环境没有达到这些标准,其中通过字幕增加监管实际上有害。我们根据我们的调查结果,设计了简单的处方,使CLIP能够更好地利用现有培训前数据集中的语言信息。