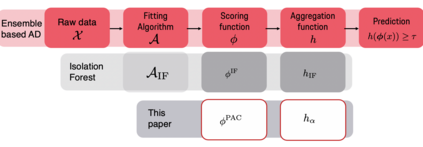
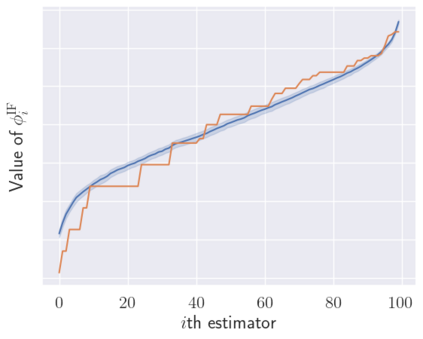
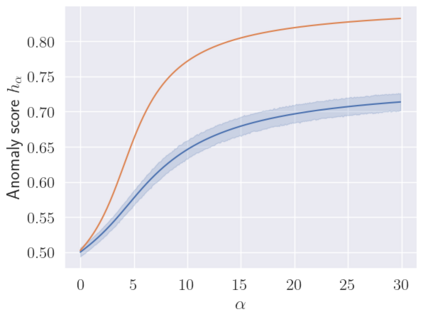
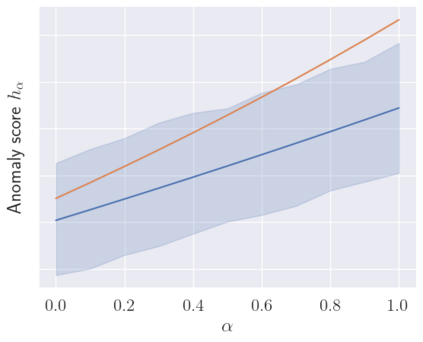
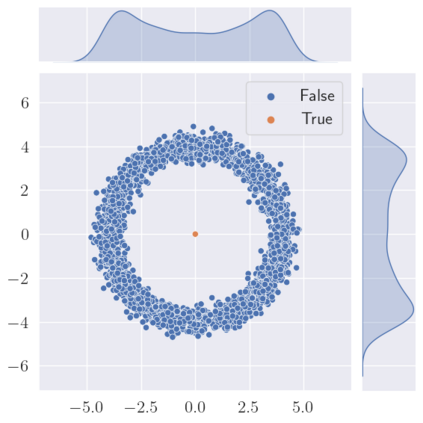
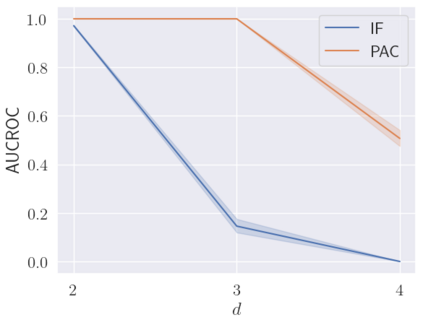
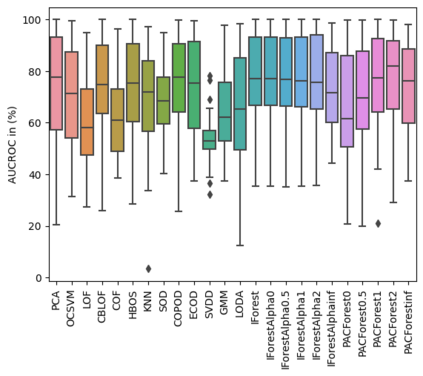
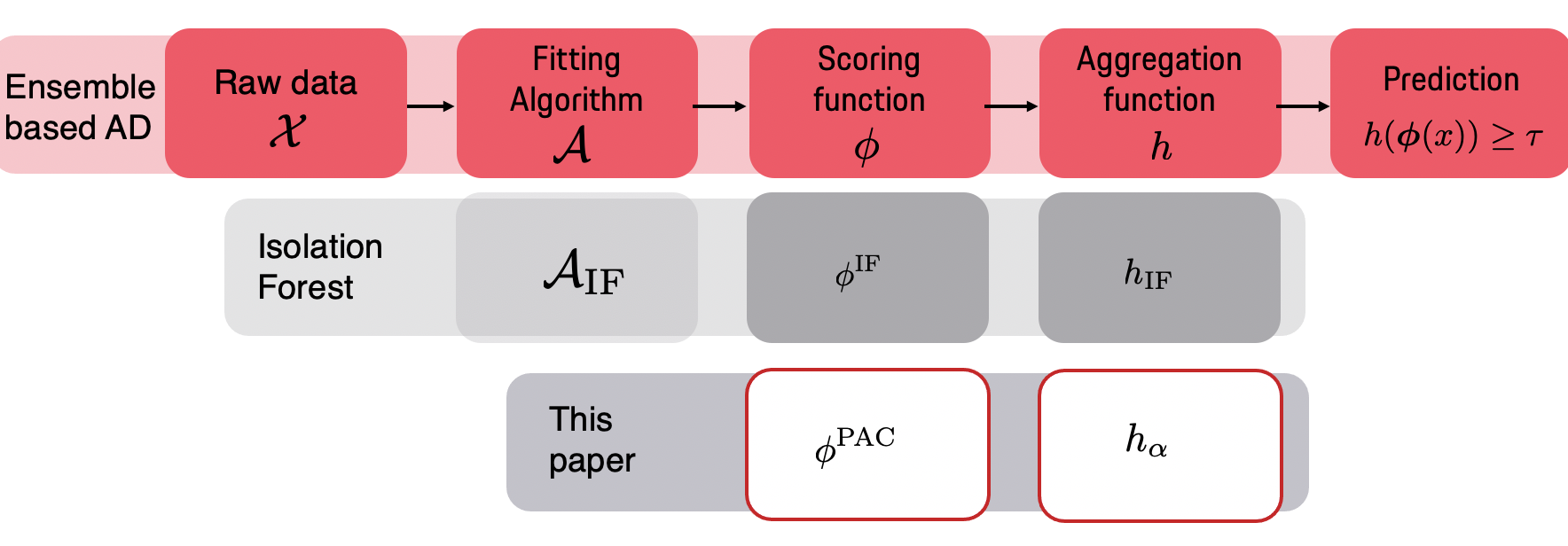
We make two contributions to the Isolation Forest method for anomaly and outlier detection. The first contribution is an information-theoretically motivated generalisation of the score function that is used to aggregate the scores across random tree estimators. This generalisation allows one to take into account not just the ensemble average across trees but instead the whole distribution. The second contribution is an alternative scoring function at the level of the individual tree estimator, in which we replace the depth-based scoring of the Isolation Forest with one based on hyper-volumes associated to an isolation tree's leaf nodes. We motivate the use of both of these methods on generated data and also evaluate them on 34 datasets from the recent and exhaustive ``ADBench'' benchmark, finding significant improvement over the standard isolation forest for both variants on some datasets and improvement on average across all datasets for one of the two variants. The code to reproduce our results is made available as part of the submission.
翻译:暂无翻译