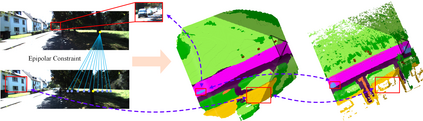
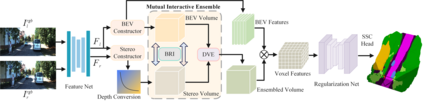
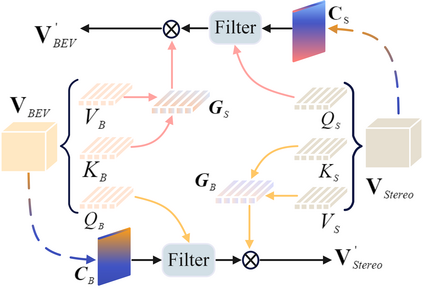
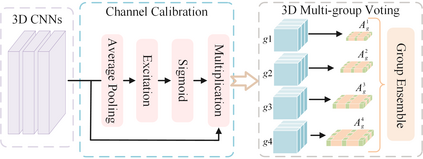
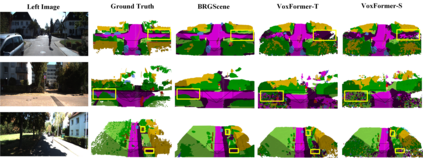
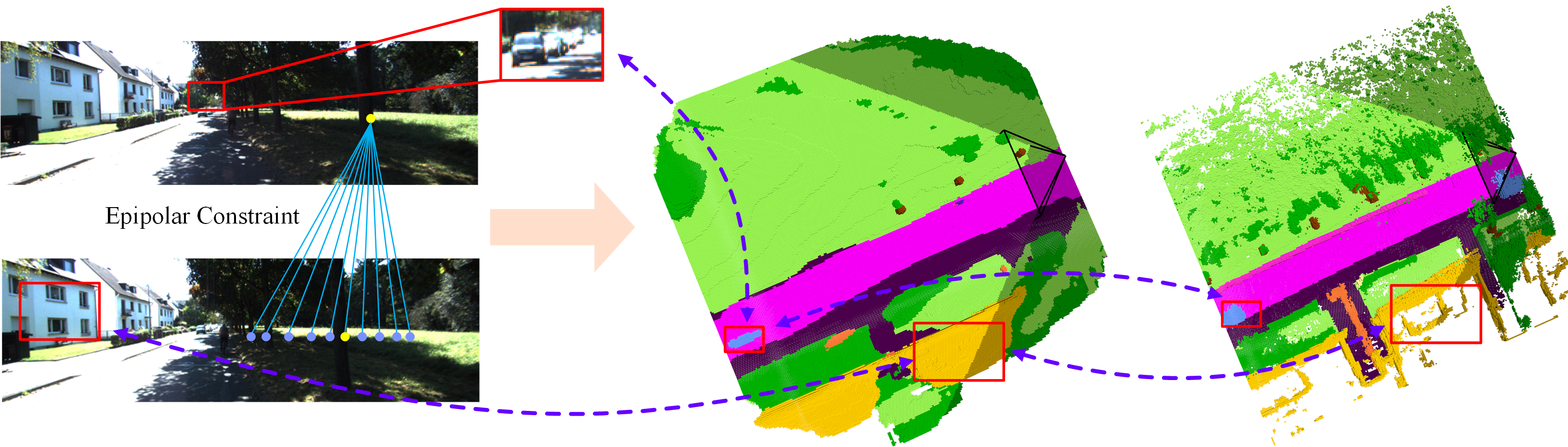
3D semantic scene completion (SSC) is an ill-posed perception task that requires inferring a dense 3D scene from limited observations. Previous camera-based methods struggle to predict accurate semantic scenes due to inherent geometric ambiguity and incomplete observations. In this paper, we resort to stereo matching technique and bird's-eye-view (BEV) representation learning to address such issues in SSC. Complementary to each other, stereo matching mitigates geometric ambiguity with epipolar constraint while BEV representation enhances the hallucination ability for invisible regions with global semantic context. However, due to the inherent representation gap between stereo geometry and BEV features, it is non-trivial to bridge them for dense prediction task of SSC. Therefore, we further develop a unified occupancy-based framework dubbed BRGScene, which effectively bridges these two representations with dense 3D volumes for reliable semantic scene completion. Specifically, we design a novel Mutual Interactive Ensemble (MIE) block for pixel-level reliable aggregation of stereo geometry and BEV features. Within the MIE block, a Bi-directional Reliable Interaction (BRI) module, enhanced with confidence re-weighting, is employed to encourage fine-grained interaction through mutual guidance. Besides, a Dual Volume Ensemble (DVE) module is introduced to facilitate complementary aggregation through channel-wise recalibration and multi-group voting. Our method outperforms all published camera-based methods on SemanticKITTI for semantic scene completion.
翻译:暂无翻译